

Hi Everyone,
I’m excited about this newsletter, which is a brief introduction to the AI chip market. It is a logical next step following my AI Primer and starting to cover the semiconductor industry with my commentary on TSMC’s Q4 2020 earnings report.
Paid subscribers will receive a separate newsletter that covers the companies which have and will continue to dominate the market. This will include both public and exciting start-ups/private companies. You can sign up for the premium newsletter here.
Housekeeping: I am taking the CFA exam next Wednesday, so there will not be a newsletter next week.
Please make sure to share this newsletter, share this post, or subscribe (if you have not already) if you like the content! You can use the buttons here to do so:
DISCLAIMER:
All investment strategies and investments involve the risk of loss. Nothing contained in this website should be construed as investment advice. Any reference to an investment's past or potential performance is not, and should not be construed as, a recommendation or as a guarantee of any specific outcome or profit.
My Primer on Artificial Intelligence ("AI") discusses the critical role that computing processing power plays in the field's development. The discussion on processing power centers primarily around one topic: semiconductors ("microchips" or "chips"). This post will explore the role chips play in the AI industry and the different types of chips. Premium subscribers will separately receive an article covering the companies participating in this part of the market. Please let me know if I have missed anything important.

AI Chip Overview
Introduction
AI chips are also known as AI accelerators (or "hardware"). These accelerators are designed specifically to optimize the performance of artificial neural network ("ANN") applications. General-purpose chips can be used to run ANN applications, but customized accelerators optimize the performance of the program. ANNs are at the heart of machine learning; multi-layered ("deep") ANNs result in deep learning ("DL") programs. The deep learning programs can be used in two main ways: 1) Training - during which the ANN is given vast quantities of labeled data with the goal of correctly identifying patterns and 2) Inference - make predictions based on new inputs from the patterns identified in the training process. Training is time and resource-intensive, requiring powerful computing resources.
In Part I of the AI Primer I mentioned how the industry emerged from the AI winter after 2013. To save the entire backstory, you can reference in Part III of the Primer how AlexNet's use of graphics processing units ("GPUs") led to a stepwise change in AI program capabilities. The parallel nature of GPU processing makes it ideal for executing a countless series of calculations, which is required to effectively run AI programs. The general-purpose GPUs (see above) do a satisfactory job, but application-specific chips lead to even better performance.
AI Semiconductor Market
Allied Market Research states the AI chip market was valued at ~$6.6B in 2018 and is forecast to grow to $91B by 2025, a 45% CAGR. From a different perspective, this report by McKinsey reveals how the AI-related chip market is expected to grow five times faster than non-AI hardware applications. As a result, the market is expected to grow from $17B in 2017 to $65B in 2025 (which would represent ~18-20% of the total market.
The market has many demand drivers including the Internet of Things, smart homes, and smart cities. The more exciting developments, which are more chip intensive, are advanced technology applications including robotics and and quantum computing (and encryption).

Chip Architecture
Chip Types and Functions
To have a discussion on the roles played and value gained by semiconductor companies from AI, I want to provide a few definitions on the different chip types and architectures.
Central Processing Units ("CPUs"): Think of the CPU as the brain of the computer. CPUs perform most of the computational functions in a computer, based on certain instruction-sets. The control unit in a CPU extracts instructions from memory, then decodes and executes them. It also directs the Arithmetic Logic Unit ("ALU") and other units on what they need to accomplish. Finally, it sends processed data back to memory. The ALU performs arithmetic and logical operations by loading data from input registers.
Graphical Processing Units ("GPUs"): GPUs were originally designed to, true to its name, improve the processing of computer graphics (and video). Originally GPUs served a complimentary (enhancement) function to CPUs, but now GPUs are necessary to optimize performance. Think about how parallel this is: it determines the makeup of each pixel in a row on the screen, row-by-row. GPUs are the most common piece of hardware for neural networks because similar to pixel image creation, the GPU can be used to perform multiple iterations of the same calculation.
Memory Chips: Memory chips can be used to both store data and process code. There are two types of memory chips: 1) random access memory ("RAM") and 2) read-only memory ("ROM"). RAM holds temporary memory, while ROM holds permanent memory that can be read, but not modified, by a processor.
Field-Programmable Gate Array ("FPGA"): FPGAs play a very important role when it comes to AI. These chips can be programmed or reprogrammed to the required functionality or application after it's already built. These chips can be used to test certain ASICs. FPGAs feature lower complexity, higher speed, volume designs, and programmable functions.
Application-Specific Integrated Circuit (ASIC): ASIC chips are purpose-built for specific applications. ASICs are faster processors than programmable logic chips or standard logic integrated circuits ("ICs") because they are designed to do one specific task.
Tensor Processing Unit ("TPU"): I'll discuss TPUs and Google below.
Reconfigurable Neural Processing Unit (NPUs): NPUs are specifically useful for Convolutional Neural Networks ("CNNs") applications, which tend to be the ANN of choice for image recognition problems.
Analog Memory-based Technology: Large amounts of analog memory devices can yield accuracy on par with GPUs in deep learning programs.
The AI Technology Stack
McKinsey developed a graphic explaining the AI technology stack much better than I could. Hardware is the foundation of the stack; the hardware consists of computing, networking, and storage. While much progress has been made in computing, there remains an opportunity for improvement in storage and networking. AI accelerators are just one of the nine layers within the tech stack; however, I would argue the chips are the most important component.
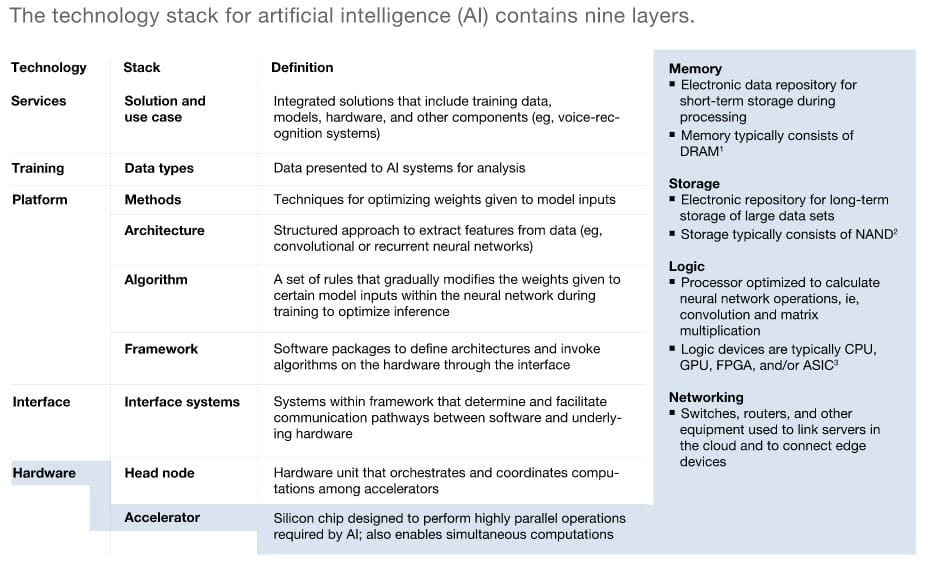
The AI accelerator architecture provides performance enhancements in computing and memory due to its purpose-built design. It's important to develop a deeper understanding of each.
Computing: Higher density chip designs enable faster and simultaneous computational functionality, which is exactly what is required for ANNs. There is no "one-size-fits-all" computing architecture since each AI use case has different computing requirements. AI applications incorporate central processing units ("CPU") along with the accelerator chips: GPUs, field programmable gate arrays ("FPGAs"), and ASICs.
Memory: The parallel nature of AI program processing creates a need for higher bandwidth (pipe size) between processors ("cores") to optimize performance. Custom AI chips rise to the challenge of increasing bandwidth size, as they allocate ~4-5x more bandwidth to the system than general-purpose chips. Memory's role in AI applications is the storage of input data, weights and other model parameters, and supplement training and inference data. Think about how much data needs to be stored when training a program; input data, correct "answers", and more as the model becomes fine-tuned. The most common type of memory is dynamic random access memory ("DRAM"). Memory is cleared every time a computer is turned off / loses access to power.
DRAM: Volatile (transient) memory that can only transmit a single line of memory and needs to be refreshed in order to prevent memory loss.
Static Random Access Memory ("SRAM"): Non-volatile (permanent) chips typically housed in mobile devices.
Erasable programmable read-only memory ("EPROM"): These chips can be erased when exposed to ultraviolet light, then reprogrammed with new data.
Programmable read-only memory ("PROM"): These chips can only be programmed once
Storage: The amount of data created by AI processes is staggering. McKinsey estimates that AI applications generate 80 exabytes (quintillion bytes) of data per year, which is expected to grow to 845 exabytes per year by 2025. Estimates indicate a 25-30% annual growth in storage requirements through 2025, more than computing and memory. Storage designs depend on whether it is being used for training or inference. Training processes require storage hardware to be able to store data as the algorithm is refined. Inference systems only require long-term storage to be used in future training processes. Data in storage remains independent of power and can only be deleted manually.
Hard Disk Drives ("HDD"): The original hard drive, takes a magnetic approach to storing data in bits.
Solid-State Drives ("SSD"): Using NAND ("Not And") flash memory, semiconductors store data by manipulating electrical circuitry. This leads to faster and smoother performance than HDDs.
NAND Flash Memory: NAND refers to the type of boolean operator and logic gate, which produces a "False" value only if both inputs are "True".
*For clarification purposes, memory refers to the short-term location of temporary data (volatile) while storage is utilized for long-term data use and access. Primary (volatile) memory is smaller, but faster, than secondary (non-volatile) storage.
Networking: While not a direct chip play, fast network speed (between the training machine and server) is important for optimal training performance. The development of 5G technology and edge networks is critical to the development of commercial AI use cases.
Chip Applications and Demand
Now that we have a baseline understanding of the types of semiconductors and the use cases for each, we can develop an understanding of the applications of each type of chip in the AI space.
Computing

Growth in computing demand for AI applications is expected to be driven by two parts of the broader infrastructure: data centers and edge networks. Data center applications will continue to play a prominent role in AI use cases. However, edge applications will start to accelerate as edge networks are built out and 5G technology becomes more widespread. The combined impact is expected to yield annual growth between 10-15% through 2025.
Data Centers: GPUs are primarily used in data centers for training applications, but ASICs are beginning to gain share and expected to make up 50% of chip solutions for data center training tasks. This should lead to customized GPUs increasingly meeting the needs of deep learning programs. Similarly, FPGAs can be used for quick turnaround or high-priority applications. For inference applications, CPUs are expected to cede share to ASICs with CPUs accounting for 50% of market demand and ASICs making up 40%.
Edge Applications: Edge training applications, which occur on endpoints (devices), are split equally between CPUs and ASICs, with ASICs expected to make up 70% of market demand by 2025. CPUs aren't expected to even be used for these applications by 2025, with FPGAs accounting for 20% of demand through its emerging role in edge training. Inference applications are somewhat differentiated, with GPUs currently and expected to continue playing a role when it comes to autonomous driving. Similarly to training applications, ASICs are expected to take share from CPUs when it comes to market demand by 2025.
The common theme is growth in ASIC market share, illustrating how the market is moving towards task-specific applications. This dynamic will come with higher costs, but also much better performance.
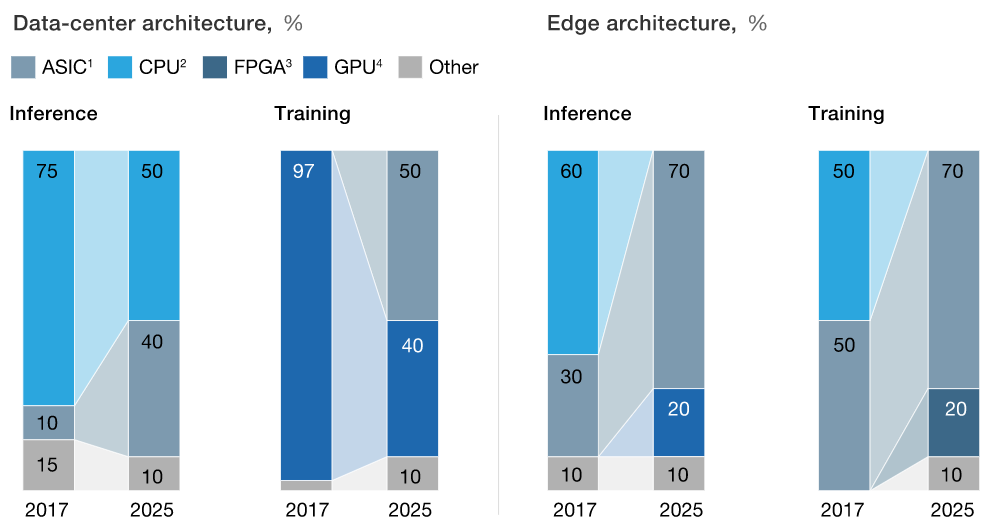
Memory
Memory annual growth is expected to lag compute, storage, and networking through 2025. The lackluster 5-10% expected growth is forecasted due to expected algorithm efficiencies in addition to capacity limitations. Current memory is typically optimized for CPUs, but developers are now exploring new architectures.
Data center demand is expected to be the main driver of short-term memory growth since high-bandwidth DRAM is needed to run AI, ML, and DL algorithms (recall, the 4-5x bandwidth increase mentioned above). The Internet of Things, autonomous driving, and 5G technology will drive demand for AI memory at the edge (DRAM). The future of memory is expected to be centered around high-bandwidth memory("HBM") and on-chip memory ("SRAM").
High-bandwidth Memory: I will conclude this article with a framework for analyzing AI hardware components. As a teaser, power requirements are one such criterion. HBM allows AI applications to process large data sets with lower power usage while not sacrificing processing speed. Nvidia and Google, two of the leading AI chip companies, have already adopted HBM as their preferred memory solution despite it being over three times more expensive per gigabyte than DRAM ($25 vs. $8).
On-chip Memory: For deep learning computing processors, storing and accessing data in DRAM or other outside memory sources can take ~100x longer than if the memory was stored on the same chip. This was the rationale behind Google allocating enough memory on the TPU to store an entire model on the chip.
Storage
As stated above, storage requirements for AI applications depend on whether it is being applied to a training or inference system. Since training requires more data than inference, it follows that there will be greater demand for training storage solutions than for inference systems.
The industry is benefitting from innovation in non-volatile memory ("NVM"), which are resulting in higher-density chips than DRAM, better performance than flash NAND, and lower power requirements than both. The NVM storage market is expected to 5-10x by 2025, expected to go from $1B-$2B to $10B.

Chip Use Cases and Performance Criteria

The above chart from McKinsey beautifully lays out the type of chips used for specific AI applications. Walking through a few of these instances indicates how effective current chip types are at achieving certain processes. Upon understanding these use cases, it follows there needs to be a methodology for analyzing the quality of chip performance. The analytical framework and key characteristics for assessing chip performance:
Power requirements: Chips that will function on a battery-powered machine need to be able to operate with minimal power consumption to maintain device integrity and maximize its lifetime. The key metric to monitor is total power dissipated ("TPD"). Physical semiconductor deployment is currently limited by chip power efficiency. The more efficient chip power usage is the more chips that can be fit into a given physical space. Of course, more chips lead to faster computing speeds or more memory, among other things.
At this point, I'll bring in the ARM vs. x86 (Intel) debate. ARM infrastructure is more "simple" than x86; ARM is based on reduced instruction set computing ("RISC") architecture while x86 utilizes complex instruction set computing ("CISC"). Simply put, ARM requires less silicon area and power compared to x86.
Processing speed: AI hardware enables faster training and inference using ANNs.
Faster training means more ML/deep learning approaches can be tested and hyperparameters (ANN architecture) can be optimized.
Faster inference is mission-critical for AI applications requiring minimal latency like autonomous driving
Development platforms: AI accelerators don't have a development board, which makes it difficult to benchmark against other chips.
Size: Chip size is a delimiting factor for how powerful AI applications can be in certain machines. IoT is a perfect example - the countless devices that will be interconnected will require chips small enough to fit in these devices.
Google's Tensor Processing Unit
The one company in the AI chip market that I will cover here is Google, while premium subscribers will get a deep dive into the major public and private players in the market. Alphabet (Google's parent company) is developing AI technology primarily in cloud computing, data centers, and mobile endpoints.
Its prominent advancement is the Tensor Processing Unit ("TPU"), its proprietary ASIC developed in 2015 specifically designed for Google’s TensorFlow programming framework. TPUs are used mostly for machine learning and deep learning. It gained a lot of notoriety after AlphaGo was run on TPUs when it beat Lee Sedol in Go.
Google’s Cloud TPU is a data center or cloud solution while its Edge TPU is designed for “edge” devices. Edge TPUs will drive the IoT, powering electronic devices from everyday items such as smartphones and tablets to industrial applications such as sensors and monitors. It is designed to run ML models for edge computing, so not only is it smaller than the Cloud TPU but it also consumes a lot less power. While Google's data center TPUs are highly effective, it seems that the Edge TPU is not yet ready for widespread commercial use. However, the Edge product is being used for high-end, enterprise machines.
Good luck in your exam and thanks for sharing your brains
Good stuff!