


Semiconductor Companies Leading the AI Revolution – Part I
The Supply Chain, Leaders, and Startups

Hi Everyone,
This is the first premium subscriber-only article, so welcome! You can also access the article on my website. To save you all the pleasantries, I wanted to let you know the next premium article will be a company analysis.
Please make sure to share this newsletter, share this post, or subscribe (if you have not already) if you like the content! You can use the buttons here to do so:
DISCLAIMER:
All investment strategies and investments involve the risk of loss. Nothing contained in this website should be construed as investment advice. Any reference to an investment's past or potential performance is not, and should not be construed as, a recommendation or as a guarantee of any specific outcome or profit.

My previous newsletter provided an overview of the AI microchip market. This article will attempt to identify which semiconductor companies will be the market leaders and what makes its technology so effective. This article will cover certain major players in relative depth, while covering other impactful companies in less detail. This is not by any means an all-encompassing list (that would be a very long read). This Part I will cover Design/IP companies, with other parts of the supply chain addressed in Part II. Unless otherwise stated, I procured this information from direct company sources (i.e. website, presentations, etc.) and refined this knowledge through discussions with one of the best semiconductor analysts I know.
Introduction
This article will begin with a quick overview of the semiconductor supply chain (which I will elaborate on in a future article). This foundation will be helpful to fully understand the AI chip market players. I will mention the companies that will be discussed in this article within where it sits in the supply chain. My overarching view of AI and semiconductors is that AI progress depends on semiconductor technology advancements, and semiconductor industry growth hinges in large part on AI progress.
Definitions
Compiler: A computer program that translates (compiles) code written in one language (the source code) into another language (the target language). The target language ends up being the language, or instruction set, that can be understood and executed by the computer’s processors. Think of the compiler simply as a translator, from a more complex language used by humans/users to a more simple language that can be understood by computers.
Run-Time: The amount of time it takes for a program to be executed, also known as the program lifecycle.
Profiling: Software or program analysis, including “the space (memory) or time complexity of a program, the usage of particular instructions, or the frequency and duration of function calls.” Profiling tools are used to accomplish this analysis.

Semiconductor Supply Chain
I learned a lot about the global semiconductor supply chain from a report published by the Semiconductor Industry Association, which I will use to explain the supply chain here.
Research and Development (“R&D”): While the industry typically followed Moore’s Law for the majority of its existence, it has now moved into the “More than Moore” paradigm. R&D companies focused on enhancing processor speed and efficiency (lower power usage) at a lower cost to keep up with Moore’s Law. Simply, the focus was on increasing chip density – fitting more transistors on the same size chip. In More than Moore, companies are focusing on innovating in assembly and packaging to mitigate the physical limitations encountered by Moore’s Law.
Design: The output of R&D serves as an input for design companies. These design companies figure out how to leverage existing semiconductor technologies to meet customer demands and create further technological advancements. There are two sub-segments of Design:
Intellectual Property (“IP”) Companies: IP companies develop and license predesigned, modular circuits. These modular circuits are sold to other chip companies to be either integrated into their existing chip designs or added as a separate component to their chips.
Nvidia: Nvidia invented the graphics processing unit (“GPU”), which is at the core of computing for AI programs. Nvidia’s CUDA parallel computing platform is the platform of choice for software developers and engineers requiring general-purpose processing. CUDA serves as a major competitive advantage for Nvidia moving forward.
Hyperscalers: Google, Amazon, Microsoft, Apple, and the other hyperscalers are all investing significant resources in their own AI chips.
Arm Holdings: Arm is a leading IP company that utilizes Reduced Instruction Set Computing (“RISC“) design. RISC is a more simple, lower power-consumption, processing family compared to Intel’s x86. ARM is an acronym for Advanced RISC Machines.
Electronic Design Automation (“EDA”) Companies: These companies provide computer-aided design (“CAD”) and related services to the IP companies. This segment of the market has benefited from the hyperscalers and other new design companies entering the market. More importantly, EDAs will see increased utilization in the “More than Moore” paradigm as companies explore more efficient packaging technologies. The EDA market is a duopoly, comprised of Cadence Design Systems (“Cadence”) and Synopsys.
Manufacturing: These companies produce the designed chips, which requires significant engineering and technical expertise. The companies have can skillfully handle chemicals and materials utilized in the production process. These companies must achieve operating scale due to high fixed costs (barriers to entry along with the aforementioned expertise) and required recurring facility upgrades to keep up with advanced technologies.
Raw Material Suppliers: These companies provide the raw wafers and chemicals to manufacturing companies that are used to produce the chips.
Wafer Fab Equipment (“WFE”) Suppliers: Provides the specialized equipment and tools used in the production process.
Assembly, Testing, and Packaging: The companies performing these functions are known as outsourced assembly and test (“OSAT”). This vertical was historically labor-intensive, but the More than Moore paradigm is centered around developing advanced packaging innovations. I see this segment becoming more important and reliant on skilled labor and engineering capabilities.
Raw Material Suppliers: These companies provide the lead frames and packaging material to OSAT companies.
Equipment (“WFE”) Suppliers: Provides the specialized equipment and tools used in the assembly and packaging processes, as well as testing equipment.

Intellectual Property Companies
Nvidia (NASDAQ: NVDA)

Nvidia created the GPU and has developed a leading position in the AI chip market as a result of the GPU’s prominent role in AI programs. Last year, Nvidia released the A100 (8th Gen GPU-series) based on its Ampere architecture. The Ampere architecture is Nvidia’s attempt to join training and inference chips into one chip family. The A100 is designed specifically for data centers and optimized for high-performance computing (“HPC”) and inference processes. According to zdnet.com, this new chip has over 54 billion transistors and is 20x faster than Nvidia’s previous leading chip, Volta.
NVDA’s major competitive advantage is CUDA: its parallel computing platform and programming model used by software developers to run general process applications on GPUs. CUDA is the software component used to run Nvidia’s GPU chips. This hardware-software combination entrenches Nvidia’s dominant position in the marketplace.
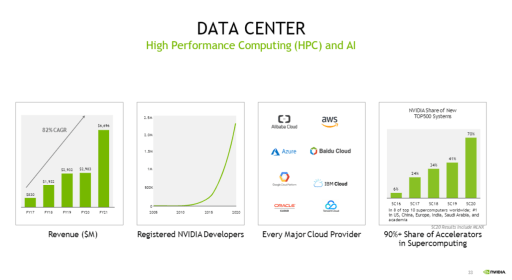
The company is a leader in data center and autonomous vehicle (“AV”) chip technologies. On the data center side, its leadership in AI/DL is evident by the 82% CAGR over the past five years and has gained adoption by the major cloud providers, along with thousands of other customers. Furthermore, Nvidia’s chips are fueling the HPC market; they are used in eight of the top 10 and two-thirds of the top 500 supercomputers in the world. As can be seen in the image above, NVDA has a 90% market share of accelerators used in the HPC market. While its autonomous vehicles segment has only grown at an 11% rate the past five years, Nvidia’s AV DRIVE hardware & software stack is well-positioned to take a share of the estimated $25B AV TAM by 2025. The NVDA Clara chip is pushing the healthcare industry forward, especially enabling AI-led drug discovery. Even more profound is its expected $100 billion data center TAM by 2024.

Finally, Nvidia has built a software development kit (“SDK”) for developers called Merlin, which is used to build AI-based recommendation systems. Another finding on zdnet is that “Merlin reduces the time it takes to create a recommender system from a 100-terabyte dataset to 20 minutes from four days.” Jarvis, the company’s conversational AI SDK, includes deep learning models that can be deployed in the cloud or at the edge.
Arm Holdings
Nvidia has reached an agreement to buy ArmHoldings from Softbank for $40 Billion, pending regulatory approval (which is a real issue). The goal of the acquisition is to create the “premier computing company for the age of AI.” As mentioned above, Arm develops and designs processor architectures, which it then licenses to leading fabless companies. Arm Holdings is essentially the Switzerland of the semiconductor market. It makes sense that many chip companies have voiced their opposition to the acquisition, stating it would remove a competition enabler in the market. Of particular concern would be to companies like Qualcomm, as ARM’s architecture is the baseline for 90% of the mobile market. The combined capabilities of NVDA and Arm would create a chip behemoth, which is why there is a meaningful probability that regulators do not approve the deal.
Arm’s RISC architecture is viewed as superior for AI applications since the more simple instruction set requires fewer transistors on the chip. As a result, chips can either be smaller or be built with more space to incorporate peripherals. The faster processing speeds and lower power consumption are somewhat offset by the increased memory consumption and longer execution times since the software requires more instructions. Due to these characteristics, the Arm architecture is better suited for mobile and AI applications, while Intel’s x86 is utilized for CPUs in desktop computers. An excellent breakdown of the differences between the two architectures, and one of my sources for this write-up, can be found here.
Hyperscalers
Alphabet (NASDAQ: GOOGL)

I may have to do an entire newsletter on Google’s contributions and successes when it comes to AI. Google is moving full-steam ahead on a variety of AI applications and projects. Whether it be AI-powered hardware, its PageRank algorithm, or its DeepMind subsidiary, Google has been at the leading edge of pushing the AI industry forward. I will focus on brevity by discussing three core concepts that make Google a major player in AI.
TensorFlow is Google’s turnkey open-source platform for machine learning programs. Its suite of tools, libraries, and resources helps software developers build and run ML applications. Additionally, it enables AI researchers to continuously innovate at the edge of the AI field; it’s a platform that serves as a launchpad for many of the most amazing developments in the field. TensorFlow is user-friendly, so much so that beginners can easily use build and train models using its Keras API. Keras is one of many APIs that can be utilized by a developer to achieve an objective. The full scope of TensorFlow can be seen in TensorFlow Extended (TFX), Google’s full production ML pipeline. TensorFlow can be deployed in servers, edge devices, or the web; TensorFlow Lite was developed by the team for mobile and other edge devices. To get a sense of the widespread application of TensorFlow, its customer base includes the companies below among others.

What I love about the TensorFlow site is that it even has a module for learning how machine learning works. If you are all wondering why there’s a delay in my next newsletter, you will know what I am doing!
Google’s TPU is a custom-designed AI accelerator application-specific integrated circuit (“ASIC”) that was specifically designed to process neural networks (using TensorFlow!). Google uses the TPU for many of its core products including Search, Gmail, and Assistant. Note, they have launched an Edge TPU but it is still nascent so I will not discuss it in much depth here. An exciting development, which shouldn’t be a surprise given it is Google, but the company is now using AI to design its chips internally to speed up the design process. The team refers to this as “architecture exploration” – the goal is performance improvement by optimizing the design of the functional elements of the chip and how they interact. You can read more about Google’s endeavor to use AI in architecture design here. The article concludes with this thought-provoking take:
The final takeaway, then, is that even as chip design is being affected by the new workloads of AI, the new process of chip design may have a measurable impact on the design of neural networks, and that dialectic may evolve in interesting ways in the years to come.
Tiernan Ray
The Cloud TPU V3 can perform 420 teraFLOPS and contains 128GB of high-bandwidth memory (“HBM”). For clarity, this means the V3 can perform 420 TRILLION floating-point operations per second. That’s 420 x 1012 for those of you counting at home. The V3 represents a 133% increase in processing speed over the V2 TPU (180 teraFLOPS) and double the memory (64 GB of HBM). A pod of the V3 TPUs contains up to 2,048 TPU cores and 32 Tebibytes of total memory, resulting in over 100 petaFLOPs (over 100 QUADRILLION = 1015) of processing speed.

Google’s subsidiary has been behind some of the most impressive achievements in AI.
AlphaGo / AlphaGo Zero: The team at DeepMind developed a program that could beat a human at a board game. Ok, it’s a little more complicated and impressive than that. Go is an ancient Chinese game of strategic thinking. While the rules are simple, the game is extremely complex. There are 10170 possible board combinations, which is more than the number of atoms in the known universe! AlphaGo beat 18x Go world champion, Lee Sedol, 4 games to 1 in 2016. But that isn’t the most impressive feat of AlphaGo. The machine actually invented winning moves, proving that it was not just a probability-calculating program, but also had a creative element to it. The team went on to create AlphaGo Zero. While AlphaGo was trained by playing against other players, AlphaGo Zero was trained by playing against itself. From the blog:
AlphaGo Zero quickly surpassed the performance of all previous versions and also discovered new knowledge, developing unconventional strategies and creative new moves, including those which beat the World Go Champions Lee Sedol and Ke Jie. These creative moments give us confidence that AI can be used as a positive multiplier for human ingenuity.
DeepMind Website
AlphaFold: DeepMind’s AlphaFold can be used to accurately predict 3D models of protein structures and has the potential to shorten research cycles across fields of biology. It was trained from 100,000 different known protein structures and sequences. It has developed to a point where it can now accurately predict a protein’s structure based on its amino acid sequence. Recently, AlphaFold was used to predict the protein structures of six of the 30 different protein structures comprising the SARS-CoV-2 virus. This helped scientists gain insight into 60% of the virus’ proteins that were poorly understood. This one practical use case is just an example of how AlphaFold is solving the protein folding problem. To summarize the scale of the problem:
But DNA only contains information about the sequence of amino acids – not how they fold into shape. The bigger the protein, the more difficult it is to model, because there are more interactions between amino acids to take into account. As demonstrated by Levinthal’s paradox, it would take longer than the age of the known universe to randomly enumerate all possible configurations of a typical protein before reaching the true 3D structure – yet proteins themselves fold spontaneously, within milliseconds. Predicting how these chains will fold into the intricate 3D structure of a protein is what’s known as the “protein folding problem” – a challenge that scientists have worked on for decades.
AlphaFold Blog,AlphaFold: Using AI for Scientific Discovery

Amazon (NASDAQ: AMZN)

Amazon launched its first AI accelerator, AWS Inferentia, at its 2019 re:Invent event. True to its name, Inferentia was designed to enable high-performance inference in the cloud at a lower cost to users. Similar to Google, Amazon’s goal is to create a turnkey solution. So, Amazon developed the AWS Neuron SDK to enable the creation of neural network models. Like Nvidia’s Merlin and Jarvis, the Neuron SDK consists of a compiler, run-time, and profiling tools that help optimize the performance of chip (Inferentia) workloads. The Neuron SDK is compatible with the most popular AI platforms (i.e. Tensorflow, PyTorch, and MXNet) and can be executed using Amazon EC2 Inf1 instances. The AWS Inferentia chips can perform 128 teraFLOPS and deliver 30% higher throughput and up to 45% lower cost per inference relative to its previous best-performing instance (EC2 G4). For clarity, EC2 refers to Amazon’s Elastic Compute Cloud. This cost-saving is extremely important since inference accounts for ~90% of ML infrastructure costs.
Fast-forward one year to the 2020 re:Invent event, during which the Amazon team announced the launch of AWS Trainium. Trainium is the custom chip training counterpart to Inferentia, which complements each other. Trainium maintains many of the same features as Inferentia: use of Neuron SDK, compatibility with other AI platforms, and run inside EC2. Trainium can also be run inside Amazon SageMaker, its ML platform. New instances will be launched this year, to support a wide range of deep learning training workloads including natural language processing (“NLP”), recommendation engines, image classification, and speech recognition. The combination of Inferentia and Trainium provides users with “an end-to-end flow of ML compute from scaling training workloads to deploying accelerated inference.” Finally, AWS is targeting 40% better price/performance compared to the current set of GPU-based EC2 instances through its partnership with Intel to launch Habana Gaudi-based EC2 instances for ML training.
Other Design/IP Companies
I want to conclude this article by providing insight into a variety of other design/fabless companies that are shaping the future of AI chips. This section will include a variety of public and private companies. To provide a smooth transition, lets start with Intel.
Intel (NASDAQ: INTC)

Leaving aside the company’s very public struggles, it has made strategic moves to become an influential AI chip company. Starting with another failure, Intel acquired Nervana Systems for ~$408MM in August 2016 as its first attempt to enter the AI chip market. However, the company scrapped the Nervana neural network processors after it acquired Habana Labs for $2B in December 2019. Habana launched its Goya Inference Processor in Q4 2018 and followed that in 2H 2019 with its Gaudi Training Processor. The Habana chips support many of Intel’s product lines including Mobileye, Movidius (vision processing units), its upcoming Xe architecture, and FPGAs. Karl Freud, Founder & Principal Analyst at Cambrian-AI Research LLC states that Intel’s software AI stack is second only to Nvidia. Additionally, the company’s 3rd gen Xeon processors contain a built-in AI accelerator for B2B and B2C.
Apple (NASDAQ: AAPL)
Apple officially moved away from using Intel processors for its most recent series of Mac laptops and desktops released in November 2020, after a 15-year relationship. The chip series used for Macs is the m-series, with this first generation being M1. This follows after Apple had been producing and using its own A-series chips for the iPhone and iPad product lines since 2010. This ensures that Apple has full control over its entire hardware/software stack, true to its nature, and ensures its entire product line runs on the same framework. Unlike Intel’s chips based on x86 architecture, Apple’s chips use ARM RISC architecture. Along with the move from Intel, Apple has contracted TSMC as its fab, which enabled the M1 series to be based on TSMCs 5nm process technology. All of these changes result in better processing performance and power consumption (thus, battery life), optimizing performance per watt. The A14 is also a 5nm chip, containing 11.8 Billion transistors, +40% over the 8.5B transistors in the A13.
What about AI? Apple started featuring a “Neural Engine” in its SOCs in the A11, a hardware component that performs AI/ML calculations. The A11 could perform 600 Billion operations per second. That quickly scaled in following chips, as the A12 and A13 could perform 5 teraFLOPS and 6 teraFLOPS, respectively. The A14 nearly DOUBLED the processing speed of the A13m, able to perform 11 teraFLOPS, while featuring matrix calculations in the CPU cores.
Advanced Micro Devices (NASDAQ: AMD)
My understanding is that AMD is still in the early innings of building out its AI chip capabilities, but its strength in the GPU market makes it well-positioned to be a major player in AI chips. The company is especially coy about its place in the AI chip market. AMD’s line of EPYC CPU server chips and Radeon Instinct GPUs are specially made to enable HPC and AI applications.
GraphCore

GraphCore is a UK-based AI/ML accelerator startup that recently raised a $222MM Series E at a $2.8B valuation. Its main product is the Rackscale IPU-Pod, targeted at providing enterprise-level AI architecture. Its IPU-POD64 can scale from regular computing to supercomputing scale. It builds upon the IPU-M2000, offering scaling of up to 64,000 IPUs. Remarkably, the IPUs can run in a disaggregated fashion through partitioning to manage multiple workloads at once, or run in a singular integrated fashion. The IPU is what GraphCore calls an “Intelligent Processing Unit,” which has scale-up and scale-out functionality. Its IPU-M2000 built with the Colossus MK2 IPU contains 450GB of Exchange-Memory and has 1 petaFLOP of AI processing power. The modular design of this next-gen solution allows customers to easily scale from one to thousands of IPUs. Its customer base already includes the likes of Dell, Microsoft, and Baidu; the company is backed by the likes of BMW and Microsoft.
The company has also designed its Poplar software framework, which was co-designed from the ground up with the IPU to ensure optimal functionality. This SDK is a complete software stack that can be integrated with existing ML frameworks, so devs can either transport existing models or even write IPU programs directly in Python of C++. I really like what I see from GraphCore; however, it faces an uphill battle to catch up with Nvidia (similar to INTC).
Cerebras

The Cerebras CS-1 is a deep learning system built for servers. The company is clear that it believes faster chips alone are not sufficient to achieve the computation speed and efficiency required for AI applications. The CS-1 system features 1) the Cerebras Wafer Scale Engine (“WSE”): a trillion-transistor processor, 2) the Cerebras System, and 3) the Cerebras software platform. The scale of the system and WSE itself is staggering. The WSE is 56x larger than the next largest GPU according to the company’s website and Popular Mechanics.

You read the above image correctly, the Cerebras WSE features 1.2 Trillion transistors. Computations inside the WSE occur in 400,000 Sparse Linear Algebra Compute (SLAC) cores, which are flexible and individually programmable. One of the really interesting features of a SLAC core, to me, is that it filters out all zero data so that it never multiplies by zero, which is a waste of energy. The WSE also features 18GB of equally distributed on-chip memory (SRAM). All of this ensures the system can run neural network algorithms with high performance.
Finally, the software platform consists of 1) the Cerebras Graph Compiler (“CGC”), 2) a library of high-performance kernels and a kernel-development API, 3) tools for debugging, introspection, and profiling, 4) clustering software. Similar to the previous software stacks we discussed, Cerebras’ software stack integrates with TensorFlow, PyTorch, and other popular ML frameworks. Since the software stack and WSE was designed in conjunction from the ground up, each stage of the CGC is designed to maximize WSE utilization. Kernels are dynamically sized so that compute resources are allocated to workloads based on its complexity. I highly recommend checking out the company’s website and product overview, the technology is really impressive.

Other Players
There are countless other ML chip players out there that would make this post egregiously long. Some of the other exciting smaller players include Tenstorrent (link to a Twitter thread I wrote up), Mythic AI, Wave Computing, Imagination Technologies, and more. I wanted to conclude with Run:AI, a software that accelerates AI workload execution. Run:AI serves as an extraction layer between different hardware and workloads. The company’s fractional GPU sharing for Kubernetes DL workloads enables users to save costs by running multiple workloads at once on a single GPU chip.
Conclusion
The proliferation of Artificial Intelligence applications requires semiconductor companies to continue innovating to enable faster and more efficient training and inference. Nvidia is one of the industry leaders, which follows from its creation of the GPU and dominance of its CUDA platform. The hyperscalers are pushing the industry forward, led by Google and Amazon but joined by the likes of Microsoft, Facebook, and others. By bringing chip production in-house, Apple has further enhanced its product capabilities. Intel initially stumbled in its move into AI, but has seemingly right-sized the ship following its acquisition of Habana Labs. The many exciting private ML companies include GraphCore, Cerebras, Tenstorrent, Mythic AI, and others.