

Hi Everyone,
I mentioned the four themes I am focusing on right now in last week’s newsletter on Unity Software. I will be developing primers on each of these themes in between the summary company analyses. Each primer will be an amalgamation of multiple newsletters, essentially a multi-part series. My goal is to have you learn with me as I start developing domain expertise in these fields. I hope you enjoy the ride.
In Part I of this primer, I will cover some of the basics of AI. This includes: 1) what is AI?, 2) the history of AI, 3) the two main types of AI, 4) how we can know if a machine is artificially intelligent, and 5) a summary of the most common application of AI, Machine Learning.
Please make sure to share this newsletter, share this post, or subscribe (if you have not already) if you like the content! You can use the buttons here to do so:
Investing Tip & Resource
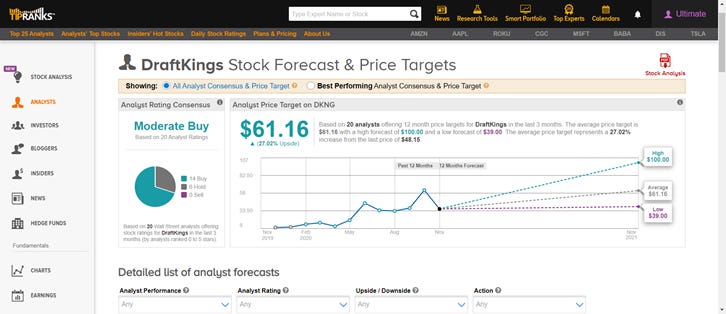
You need to know the consensus view of a stock in order to make contrarian bets. I believe alpha is created by 1) having a differentiated perspective, and 2) being right. TipRanks is the best resource I’ve found for better understanding Wall St. expectations. I recently used it when I was researching DraftKings and found it immensely helpful (snapshot below).
I prefer their Ultimate plan so that I get access to all of the features provided on the website. They are having a 20% off sale next Friday, 11/27, which would be a great opportunity to get a subscription. I highly recommend checking it out!
DISCLAIMER:
All investment strategies and investments involve risk of loss. Nothing contained in this website should be construed as investment advice. Any reference to an investment's past or potential performance is not, and should not be construed as, a recommendation or as a guarantee of any specific outcome or profit.
With that, please enjoy Part I of the primer on Artificial Intelligence!
Artificial Intelligence Primer, Part I: An Overview of Artificial Intelligence

What is Artificial Intelligence (“AI”)?
Artificial Intelligence refers to the broad discipline and field of creating “intelligent” machines. The term “artificial” does not mean “fake” intelligence. Artificial in this context means that it is not natural intelligence endowed upon humans and animals (I know, perfect set up for human intelligence jokes). It has become an umbrella term that encapsulates the ambitions of humans to build machines that can match, and subsequently exceed, the full range of human cognition.
We can think about the goals of AI as: 1) getting computers to think like humans, 2) simulate our cognitive thinking and decision-making abilities, and 3) have the computer utilize these accomplishments to take actions as humans would. The end-state is enabling computers to be better and faster problem-solvers than humans, in order to improve society as a whole.
You will know if a machine has artificial intelligence if it can: 1) interpret data, 2) potentially learn from the data, and 3) apply that acquired knowledge to adapt and achieve specific outcomes.
It is important to understand that the fundamental building blocks of AI are algorithms (“algos” or “agents”). An algorithm is a sequential list of rules to be followed in order to solve a problem or complete an objective. The key word here is sequential. Think about an algorithm as an instructions manual. As an example, say you are explaining how to build a house to someone. You wouldn’t say, “first, put the roof on, then lay tile in the kitchen, then build the foundation, then put in the skylights.” Instead, you would start with the foundation and work your way up. Computers are extremely literal and do exactly what they are told, so order matters!
An Analogy to Understand AI
You can think of machines with AI as babies: it knows nothing when it is created. Babies use their senses to perceive the world and their bodies to interact with it, then learn from the consequences of their actions. Babies are gathering millions of data points as they learn basic human functions: speaking, walking, eating, etc. However, modern AI systems don’t have senses or bodies to judge all of these data points; they are simply programs and machines. So, modern AI requires: 1) a lot of data, and 2) data labels with whatever the AI is trying to learn, 3) a powerful enough computer to process and make sense of all the data.
A Brief History of Artificial Intelligence
The term “Artificial Intelligence” was coined in 1956 by a computer scientist named John McCarthy, to name the “Dartmouth Summer Research Project on Artificial Intelligence” (or simply, the “Dartmouth Conference”) that he was organizing. The Dartmouth Conference was essentially an 8-week brainstorming session, where computer scientists, cognitive psychologists, and mathematicians, came together to clarify and develop ideas about “thinking machines”. These experts initially greatly misunderstood the quantity of data and processing power that would be required to solve complex problems.

The AI Winter
The lack of processing power and appropriate data left the field of Artificial Intelligence mostly stagnant with no meaningful advancements until 2010-2012. This stagnant period is known as the AI Winter, which is a quiet period of research and development for AI (whether it be investment / funding or physical processing constraints).
The AI Revolution
There was no “big bang” for AI, when all of a sudden Netflix could recommend the next movie you should watch. Rather, modern AI has progressed due to the compounding of many small decisions in addition to two major technological developments, which will be discussed below.
Tech Advancement 1: Increase in computer processing power (to process the data).
The IBM 7090 was the most advanced computer at the time of the Dartmouth Conference. The IBM 7090 filled up an entire room, stored data on cassette tapes (remember those!), and took instructions using paper punch cards.

IBM 7090 It could perform 200,000 operations per second. Not bad considering it would take a human 55.56 hours to perform the same number of operations assuming one operation per second and no breaks.
The A14 Bionic chip in the iPhone 12 can perform 11 TRILLION operations per second. That is 55,000,000x more than the IBM 7090! However, what about comparing the IBM 7090 to its modern equivalent?
Summit, which became the world’s fastest modern supercomputer in 2018, doing computational functions similar to the IBM 7090, can do over 200 QUADRILLION operations per second (or, 200 petaflops). In other words, a program that would take Summit one second to compute would have taken the IBM 7090 31,687 years to compute.

I will be putting together a primer on semiconductors (the technology behind electronic devices) in the future, since the success of AI depends on the continued development of semiconductor technology. For our purposes in this newsletter, it is just important to know that the speed of a computer is directly linked to the number of transistors it has to do operations. Which leads me to the concept of Moore’s Law. Moore’s Law states that the number of transistors that can fit in the same amount of space (to simplify, the speed of computer processing) doubles every ~18-24 months.
Computers started having enough computing power to mimic certain brain functions with AI in 2005. But a powerful computer is meaningless for AI unless it has the appropriate quality and quantity of data to process and learn from.
Tech Advancement 2: The Internet and Consumer Facing Websites
You created data in the process of reading this newsletter. Everything you do on the Internet generates data! Many events offline are eventually uploaded to the Internet, as well, creating more accessible data. The impact of data quantity on AI algorithm quality will be covered later in this series. However, knowing that AI algorithm quality is related to the quantity of data used to train a model is a good place to start.
The IDC projects the cumulative sum of the world’s data to grow from 59 zettabytes (“ZB”) in 2020 to 175ZB by 2025, for a CAGR of 24%. Humans have a hard time conceptualizing very large and very small numbers. So if it’s helpful, a zettabyte is a trillion gigabytes. Now multiply by 175…
An important note is that 90ZB of data is expected to be generated from IoT devices.
Additionally, the “IDC predicts the average person will have nearly 5,000 digital interactions per day by 2025,” an increase from the ~700-800 that people average today.

Statista Historical and Projected Data Volume

Natural Power Law - Compounding: The last point I want to emphasize is the dramatic affect of compounding. 90% of all data in existence today was created in the past two years. Extrapolating out data growth reveals a pathway to better AI systems. However, as will be discussed later in this primer, the laws of physics present a potential constraints for data processors to keep up.

The Different Types of AI - A Summary
There are generally thought to be two different types of AI: 1) Narrow (“Weak”) AI, and 2) General (“Strong”) AI (“AGI”).

Narrow AI
Narrow AI systems are dedicated to executing a specific and defined task and continuously improving its ability to execute that task. Most of AI today is Narrow AI. Weak AI tends to be software that automates an activity typically performed by humans. Most of the time, this software exceeds human ability in efficiency and performance.
For a fun example: In the scene below, a machine with narrow AI would have been able to correctly wrap all of the chocolates while Lucy and Ethel struggled to keep up. Although, a machine successfully wrapping the chocolates wouldn’t be as funny.
Other not so funny examples include:
Autonomous Driving Vehicles: Self-driving cars already exist today, thanks to the likes of Google and Uber (although Uber is reportedly in talks to sell its ATG unit to Aurora).
Virtual Assistants: Siri, Alexa, Google Assistant, and Cortana are all examples of virtual assistants designed to provide us with information when requested.
Image / Facial Recognition: AI systems that can verify identities.
General AI
General AI is the key building block to developing more comprehensive machine learning. A machine with AGI is able to have a broader perspective than Narrow AI so that it has the reasoning capabilities similar to a human. The goal is to enable machines to make decisions based on its own learning rather than previous training; utilizing training when necessary, but always choosing the optimal solution path. Referring back to our baby analogy, the machines (like babies) should be able to learn and develop cognitive reasoning skills through its experiences. While we are still far away from this objective, scientists and engineers have been making notable progress (don’t get scared).
So, how can we know if a machine has General Artificial Intelligence? Luckily, there are four predominant tests of AGI that encapsulate the primary definition of this AI type and determines whether in fact a program constitutes AGI.
AGI Tests
The Turing Test: First developed in 1950 by English computer scientist Alan Turing, this test determines a machine's ability to exhibit intelligent behavior similar to, or indistinguishable from, that of a human. It was originally called the imitation game, designed as follows:
A human evaluator would judge the natural language conversations it had between 1) a human, and 2) a machine designed to generate human-like responses.
The evaluator would be aware that one of the two partners in the conversation is a machine, and all participants would be separated from one another.
The conversation would be limited to a “text-only channel” such as a computer keyboard and screen so the result would not depend on the machine's ability to render words as speech.
If the evaluator cannot reliably tell the machine from the human, the machine is said to have passed the test.
The main criteria for being recognized as an AGI is that the AI program needs to be able to win the the $100,000 Loebner Prize. The Loebner Price can be won by first program that that can pass an extended Turing Test involving textual, visual, and auditory components. The contest started in 1990 and has not had any winners. Once the $100,000 (Grand Prize) is won, the annual competition will no longer continue.
The Coffee Test: Making coffee is a routine task that most of us perform in our daily lives. So in 2007, Apple co-founder, Steve Wozniak, stated that a robot would be truly intelligent if it could walk into any home and figure out how to make a pot of coffee.
The Robot University Student Test: This test proposed by Ben Goertzel requires an AI machine to be enrolled in a college and earn a degree using the same resources as other students enrolled for the same degree. It would need to study all of the required subjects and pass all the exams and tests required of human students to receive a degree. Bina48 was the first ever AI to complete a college class in the fall of 2017, from the University of Notre Dame de Namur University (NDNU).
The Employment Test: In 2005, computer scientist Nils John Nilsson suggested an alternative to the Turing Test. The Employment Test would show that “machines exhibiting true human-level intelligence should be able to do many of the things humans are able to do”, including human jobs.
Machine Learning (“ML”)
Machine learning is the most common application of AI. It enables machines to automatically learn and improve from experience without being explicitly programmed. ML focuses on the development of computer programs that can access data and use it for their own learning.
There are four types of Machine Learning (which I will cover more in-depth in an ML deep dive):
Reinforcement learning
Unsupervised learning
Semi-supervised learning
Supervised learning
Reinforcement Learning
Reinforcement learning is a programming methodology that trains algorithms using a system of reward and punishment. The program learns by interacting with its environment, so no direct human interaction is required. It learns by receiving rewards for performing a task correctly and penalties for performing a task incorrectly. These algorithms (agents) learn by seeking the solution that maximizes its rewards and minimizes its penalties. However, it’s not that simple. Context is important in reinforcement learning because maximum rewards / minimum penalties are contingent on the situation.
There are three components to a reinforcement learning system:
Algorithm/agent: This is the AI program that will learn and make decisions.
Environment: Refers to everything the agent interacts with.
Actions: What the agent can actually do.
A program will go through a process of trial and error to determine the optimal pathway; the steps that lead to the greatest rewards. This process repeats many times over, known as a Markov Decision Process (“MDP”). For simplicity, I’d define the MDP as a memory-less, random process, meaning prior solutions don’t influence the algorithms future solutions. The program learns through reward feedback, or the “reinforcement signal”.
An example of reinforcement learning is training your dog to go to the bathroom outside. When the dog waits and then goes to the bathroom outside, the good doggo gets a treat. If instead, the pup decides to leave a present for you inside the house, you scold the poor boy. The dog eventually learns that he’ll get a treat if he waits to go to the bathroom until he’s outside. Mission accomplished - you used reinforcement learning to train your dog to go to the bathroom outside.
Unsupervised Learning
Unsupervised learning enables a computer to find patterns without a dataset of correct answers to learn from. The algorithm utilizes data without historical labels (“tags”) to find patterns where humans don’t. Unsupervised learning is appropriate in situations when the “right answers” are either unobservable, impossible to obtain, or there isn’t even a “right answer”. Once again referring back to our baby example: algorithms engage with a problem only having its basic logic programming, so it knows nothing at the start.
Since the data provided to a program for unsupervised learning does not have historical tags, the system is not given a pre-determined set of 1) outputs, 2) correlations between inputs and outputs, or 3) a “correct answer.” The algorithm must figure out what is occurring by itself since it has no points of reference. So, what it does is explore the data and identify patterns.
Unsupervised learning is more complex, and thus has been used less frequently, than supervised learning (below). However, unsupervised ML programs are seen as the future of AI because it moves closer to AGI (and away from Narrow AI). You can think of unsupervised learning as machines teaching and learning themselves. So, unsupervised learning is ideal for transactional data like customer purchasing patterns, where there is no “correct answer” and no patterns have been identified yet. The program can then find patterns and group customers accordingly. Then, each group of similar customers could then be targeted for specific ad campaigns based on their spending patterns.
Semi-supervised Learning (SSL)
To state the obvious, semi-supervised learning is a mix between supervised and unsupervised learning. Usually the reference data needed for solving the problem is available, but it is either incomplete or somehow inaccurate. SSL programs are able to access the available reference data and then use unsupervised learning techniques to fill the gaps.
SSL uses both labeled and unlabeled data. The AI is trained on, and learns from, the available labeled data to then make a judgement on the unlabeled data. Just like unsupervised learning, the goal is for the program to find patterns, relationships and structures. Including a lot of unlabeled data in the training process often improves the precision of the end result. Additionally, this method allows for data scientists to save on time and costs (by not having to assign information and labels themselves).
Supervised Learning
Supervised machine learning programs learn from explicit example. These programs can take what it has learned in the past and predict future outcomes by applying its learnings to new labeled data. From here forward we can refer to the two different types of data sets. Training data sets are implemented to build a model - to teach the algorithm. Test (or Validation) data sets are used to validate, or check, the model that was built. It’s important that this data is mutually exclusive (i.e. there’s no overlap).
Supervised learning requires that 1) the algorithm’s possible outputs are already known and 2) the data used to train the algorithm is already labeled with correct answers. The algorithm learns through the training data by comparing its results with correct outputs provided by the data set. When the program finds errors, it adjusts the model to improve the probability of the output being correct the next time (more on this later in the primer). The validation data is then fed into the system and checked for accuracy. At this point, the model can be tweaked and improved or you have a finished model.
It is appropriate to use supervised learning in applications where historical data can predict likely future events. A simple example of supervised learning can be as follows: you give Suzy a set of flashcards with multiplication problems on the front and answers on the back of each card (the training data). She gets some right, and puts those cards in one stack, and puts the cards she got wrong in another stack. She then goes back through the stack she got wrong (adjusts her model) and repeats until she gets them all right. Then you give her an exam of multiplication problems not contained in the flashcards (the validation data set). This process can be repeated until Suzy learns multiplication.
Summary
In Part I of this primer on Artificial Intelligence, we 1) discussed what Artificial Intelligence is, 2) covered a brief history of AI, 3) reviewed the two main types of AI, 4) figured out methods for determining how we can tell if a machine has AI, and 5) introduced a summary of machine learning, the most common application of AI. I hope this was highly informative for you. Please leave a comment if you think I can do a better job simplifying these concepts or if you have any other feedback! I’ll be back next week with Part II of this Artificial Intelligence primer.
Also selfsupervised learn is immensely important in reducing the amount of required data for supervised learning. Fx language models are to a large extend based on learning to predict the next token/word in a sentence. To do that well the model must have a good understanding of how to construct a sentence, paragraph etc.
Thx very interesting. I practice ML i generic term that encompass all kind of classical predictive models and classification fx linear regression, decision trees.