

Hi Everyone,
Once again, resending Part III of this Primer to ensure you all received it. It seems that for now I will be sending the newsletters out through substack, and can link to my website.
For a refresher, you can read read Part I and Part II. You can also view these newsletters on my website.
DISCLAIMER:
All investment strategies and investments involve risk of loss. Nothing contained in this website should be construed as investment advice. Any reference to an investment's past or potential performance is not, and should not be construed as, a recommendation or as a guarantee of any specific outcome or profit.
With that, please enjoy Part III of the primer on Artificial Intelligence!
Artificial Intelligence (AI) Primer - Part III
The Basics of Artificial Neural Networks
Definitions
Batch Size: Number of training samples from the training dataset that will pass through the model before the network's internal parameters (e.g. weights) are updated.
Epoch: Number of passes of the entire training dataset the ML algorithm will complete. Datasets are usually grouped into batches.
FLOPS: Floating-point Operations per Second, the unit of measurement that calculates the performance capability of a supercomputer.
Hyperparameter: Configuration variable external to the model used during training to estimate the value of model parameters. It is defined manually before the training of the model with the historical data set. Hyperparameters affect the speed and accuracy of the learning process of the model. The hyperparameter values are pre-set, independent of the data set, and do not change (automatically) during training. They are not part of the final / trained model.
Hyperparameters include batch size, number of epochs, learning rate, inter alia.
Iteration: Number of times the algorithm's parameters are updated. Typically, a single iteration of training a neural network includes: 1) forwardpropagation, 2) calculating the loss / cost function, 3) backpropagation, and 4) adjusting the model weights. Training of a neural network will require many iterations.
If the batch size is the whole training dataset then the number of epochs equals the number of iterations. Practically, this is rarely the case given the magnitude of data required for neural network algorithms. The mathematical relationship is d*e = i*b [d = dataset size, e = number of epochs, i = number of iterations,b = batch size].
Learning Rate("Step Size"): A configuration parameter (hyperparameter) that determines the degree to which a weight gets adjusted. It's called the step size because it controls the "step" or change made to network weight for a given error.
Parameter: A variable whose value is estimated from the dataset, learned during training from the historical data sets. They are internal to the ML model and the accuracy of parameters dictates the quality of the model. The estimated value of the parameter is saved with the trained model.
Parameters include weights (between nodes) and biases (thresholds).
PetaFLOPS (PFLOPS): A computer system capable of performing one quadrillion (1015) floating-point operations per second. To match what a 1 PFLOPS computer system can do in just one second, you'd have to perform one calculation every second for 31,688,765 years.
Petaflop/s-day (pfs-day): Consists of performing 1015 neural net operations per second for one day, or a total of about 1020 operations.
Overview
Artificial Neural Networks ("Neural Networks" or "ANN") are computing systems inspired by the biological neural networks that comprise animal brains. An ANN is comprised of a collection of connected units ("nodes") called artificial neurons, which loosely model the neurons in a biological brain. The takeaway: neural networks are comprised of many connected nodes and each node functions as a neuron, similar to neurons in the human brain. A neural network is thus a series of algorithms (mathematical functions) that emulate how a human brain functions. It is the most common and powerful form of Supervised Learning to perform classification tasks. As you will see, neural network technology has advanced to a point where Unsupervised Learning is being utilized.
What is the goal or purpose of ANNs? Like all other SL programs, it is trained with a series of labelled data. Think of it as having the test and answer key, so that it knows the right answer to every "question." At a high level, it is to recognize relationships between vast amounts of data to correctly classify the data. This process requires a lot of training data and computer processing power. It requires so much data that it started becoming the most dominant form of Supervised Learning only after the industry had a break through of how to increase compute power in these models by using GPUs alongside CPUs.
To understand ANN, we need to go back to how computer scientists first attempted to accomplish Supervised Learning ("SL"). Please refer to Part II of this Primer for a recap on Supervised Learning. These computer scientists were mostly inspired by human brains. Specifically, they were interested in cells called neurons because our brains have billions (~86B) of them.
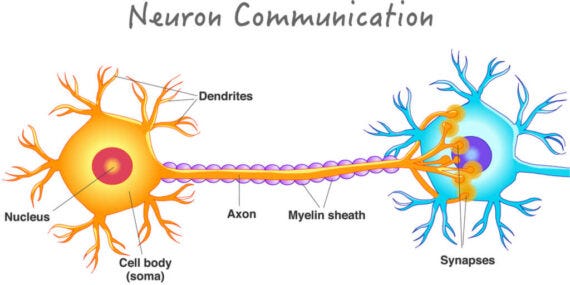
What is a Neuron?
Think of neurons as information messengers. They use electrical impulses and chemical signals to transmit information between 1) different areas of the brain, and 2) the brain and the rest of the nervous system. Pretty important, right? A neuron is a cell that consists of three parts: 1) cell body ("Soma"), 2) Dendrites, 3) Axon
Cell Body: The neuron's core - which carries genetic information, maintains the neuron's structure, and provides energy to drive activities.
Dendrites: Where a neuron receives input from other cells.
Axon: A cable through which electrical impulses from the neuron travel away to be received by other neurons.
The Axon of one neuron is connected to the Dendrites of another neuron by a small gap called a Synapse. Neurons communicate with each other by passing electric signals through Synapses.
How exactly do these neurons communicate? As one neuron receives electrical signals from another neuron, the electrical energy inside of its cell body builds up until a certain threshold is crossed. Then, the electric signal moves down the Axon and is passed to another neuron. At this point, the process repeats.
The Perceptron
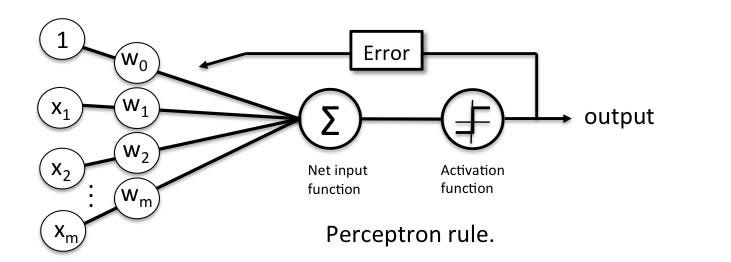
The goal of early computer scientists was not to replicate the entire brain, but rather just one neuron. In 1958, a psychologist named Frank Rosenblatt was inspired by the Dartmouth Conference (discussed in Part I) to create an artificial neuron. The result - Rosenblatt went on to create the first perceptron. A perceptron works as follows:
The artificial neuron receives a set of inputs (x), each multiplied by different weights (w)
The weights correspond to the strength of each signal (importance of input); they often start as small random values, such as values in the range 0 to 0.3
The threshold (see above) for the artificial neuron is represented by a special weight called the bias(b). The bias can be thought of as an input with a value of 1, which is then weighted
The higher / lower the bias, the less / more eager the neuron is to fire
Net Input ("Sum") Function: Each input (x) is multiplied by its respective weight (w), which is all added together
Activation ("Transfer") Function: A mathematical function that governs the threshold at which the neuron is activated and strength of the output signal, taking into account the bias and the Sum Function.
There are different functions that can be used; the most common is the step function
Step Function: Only outputs a 0 or 1 (binary); if the sum of x*w>b, the output will be a 1
For my math intensive readers out there, think about it this way:
The perceptron is a function that maps its input (x), multiplied with the learned weight coefficient (w), which creates an output value (f(x)).

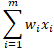
w = vector of real-valued weights
x = vector of input x values
m = number of inputs to the Perceptron
b = bias
*If the sum of all input values multiplied by their respective weights is greater than the bias, the function will produce a value of 1 (or, "True"). Otherwise, it will produce a value of 0 ("False). This is a Boolean output.
Juxtapose this back to how neurons communicate. The "electrical charge" amount is the sum of each x input with its respective weight (formula on the right). The bias is the neuron's threshold. If the electrical charge (sumproduct of x and w) exceeds the threshold (bias), the electrical charge moves to the next neuron (we get a 1 or "True" output). Otherwise, the electrical charge stops at that neuron (we get a 0 or "False").
Structure of a Neural Network
As stated above, Artificial Neural Networks are built as a connection of many nodes. Each node functions similar to a neuron, which computer scientists have replicated with a Perceptron. So, neural networks are just the intertwining of many Perceptrons. This is the reason why neural networks are also called multi-layered perceptrons. A column (or row) of neurons is called a layer and one network can have multiple layers. The architecture of the neurons in the network is often called the network topology. All neural networks are made up of three types of layers: 1) Input Layer, 2) Hidden Layer(s), and 3) Output Layer:
Input Layer: Receives input data represented as numbers
Each input node (neuron) represents a single feature. Features are the elements of the input vector. In simple English, features are characteristics of the data set.
Example: The goal of your neural network is to classify people as either men or women. The features would be things such as height, weight, foot size, etc. Each input node would be dedicated, one for one, to one of the characteristics.
Hidden Layer(s): Intermediate layer(s), between input and output layers, where all the computation is performed.
Output Layer: Produce the result(s) for given inputs. These results are the predicted value(s) from the model. The number of nodes in the output layer is based on the number of potential classifications the model is trying to solve for.
Example: A neural network used to determine if an image is a dog or a cat would have two output nodes. One for dog and one for cat.
Each layer can contain any number of nodes. The input layer is dependent on the number of features in the program. The output layer is dependent on the type of program and analysis being run.

Notice how each blue dot (input layer node) is connected to each of the three dots (nodes) in the first hidden layer. Each of those nodes is connected to each node in the next layer, et cetera. To bring the conversation full circle, each green dot (hidden layer node) is a perceptron function.
Let's focus on the top green node in either of the diagrams. All the nodes from the previous (input) layer (blue) are connected with it. All these connections (black arrows) represent the weights (impact). All the node values from the blue layer are multiplied by their weight, which is all added together resulting in a value for the top green node. This green node has a predefined activation function. As detailed above, this function defines if this node will be “activated” or how “active” it will be, based on the resulting value and the bias. In the image below, the circle containing sigma (Σ) is our green node.
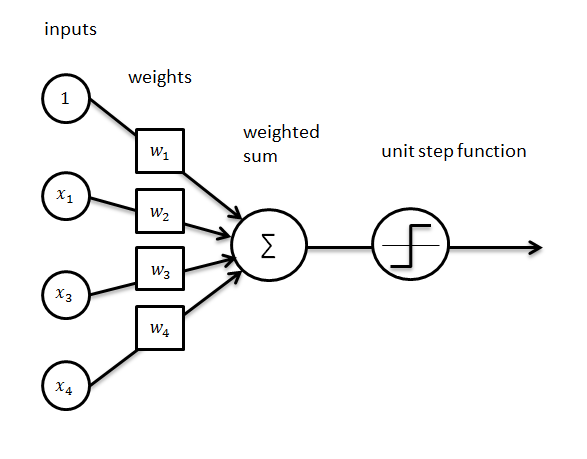
Without getting into the math, this process occurs for every node and connection in the network until the output layer is reached. Depending on the type of activation function used and the number of classifications the model is trying to solve for, the output value chosen is the one that results in the highest ending value (or, probability of being right). But what if the model result is wrong? After all, neural networks are refined through the process of making errors.
To investigate the training process, we can think of a neural network of having two separate parts: 1) architecture and 2) weights. To specify, the architecture consists of the neurons and how they are connected.
Model Training and Predictions
Training
The neural network training process is iterative, passing each example in the training data forward then back through the layers. The passing forward of the data is called forwardpropagation; the passing backwards is backpropagation.The weights and other network parameters are usually set randomly to start. The purpose of backpropagation is to optimize network parameters based on the error from the model output. We can break the training process into sequential steps:
Step 1:Forwardpropagation: occurs when a training data example is sent across the entire neural network for a prediction to be calculated as the output.
The input data is sent through the network so that all the neurons apply their transformation functions to the information they receive from the previous layer of neurons.
The resulting information is then sent forward to the neurons of the next layer.
The data crosses all the layers and all neurons make their calculations
This process culminates in a category (label) prediction in the output layer for the input data.
Step 2: A cost (loss) function estimates the error (or loss) of the model. The cost function compares and measures the the predicted result relative to the correct result (based on the label containing the expected value). The optimal result is zero cost, meaning no difference between the estimated and expected value. The smallest possible value of the loss function is called the global optimal solution.
Step 3: Backpropagation: once the loss has been calculated, the loss information propagates backwards to all the neurons in the hidden layers that contribute directly to the output. Each neuron only receives a portion of the total signal of the loss. The amount of the signal communicated to a neuron is based on its relative contribution to the error output from forwardpropagation. This process is repeated backwards sequentially until all the neurons in the network have received a loss signal that describes their relative contribution to the total loss.
Step 4: After the error information is backpropagated, the weights of connections between neurons are adjusted based on the learning rate. The adjustments are done to make the loss as close to zero as possible for the next iteration. This is done with a technique called gradient descent. Think of gradient descent as an iterative optimization algorithm for finding the minimum value of a function (the loss function!). The gradient descent algorithm adjusts the parameters (weights, biases, etc.) in the network incrementally based on the derivative (gradient or "slope") of the loss function. This process enables the network “to descend” towards the global minimum (global optimal solution), at which point the model will have its optimal weights.
Batch (Vanilla) Gradient Descent: Calculates the error for each example within the training dataset. However, the model is updated only after all training examples have been evaluated. This is the process referred to above, where the batch size is the whole training data set (epoch = iterations).
Stochastic Gradient Descent("SGD"): The preferred training algorithm for neural networks. The model parameters are updated for each training example, one by one. The advantage of SGD is the frequent updates enable a detailed, more transparent rate of improvement. However, as you could imagine, this is much more computationally intensive than batch gradient descent.
Mini-Batch Gradient Descent: The most common training algorithm since it combines aspects of batch and SGD. The training dataset is split into small batches and the algorithm performs an update for each batch. So, there is a balance between the robustness of SGD and the efficiency of batch gradient descent.
Step 5: Repeat the steps above for many epochs until the model has achieved the desired level of accuracy, precision, and/or recall. A network may be trained for tens, hundreds, or thousands of epochs.
Step 6:Prediction: After all, that is the whole point of developing AI models. The model is ready to make predictions once it has been trained sufficiently. Predictions can be made on test or validation data in order to estimate the model quality on unseen data. When the prediction quality is satisfactory, it can be deployed operationally to make continuous predictions.

To Summarize the Process:
Start with random values for the network parameters .
Pass a set of input data through the network, resulting in a prediction.
Compare these predictions with the expected label values (correct answers) and calculate the loss (differential).
Run the backpropagation, propagating this loss to all of the parameters that make up the neural network.
Use the propagated information to update the parameters of the neural network with the gradient descent with the objective of reducing the total loss and create a better model.
Continue iterating through these steps until the result is a satisfactory model.
Characteristics of Neural Networks
The Power of Neural Networks
The power of neural networks is their ability to learn a mapping pattern, then utilize that mapping to correctly categorize all data. Neural networks have the unique ability to learn how characteristics in training data best relate to the output variable, the predicted value. This is representation power, which is the ability of a neural network to assign proper labels to a particular dataset and create well-defined, accurate decision boundaries for that class. Mathematically, these networks can be thought of as an excellent means of approximating behavior of any complex function.
The multi-layered structure (architecture) of neural networks drives its predictive capabilities. The data structure can learn to represent features at different scales and combine them into higher-order features (i.e. from lines, to collections of lines, to shapes, to objects). From the process detailed above, it should be apparent that the quality of neural networks depend on the 1) quantity of training data and 2) number of times the model is trained (epochs). Given increased Internet penetration globally, digitization of core components of every day life, and the build out of new technologies (i.e. 5G, IoT, edge computing, etc.), data availability is not an issue for progress in neural networks. The main bottleneck is computer processing power.
The Current Drawbacks of Neural Networks
There are currently a few overarching disadvantages, or drawbacks, of neural networks:
Black Box Problem: Increasing the number of hidden layers built into the network increases the model complexity and the calculations being utilized. This usually leads to more accurate outputs as the model is more dynamic. However, each additional layer (of complexity) limits our ability to understand why the model generated a certain output. This is an issue for things in our lives that require human interpretation. For instance, every consumer would demand to know why a loan application was approved or denied. Neural networks that are too complex, resulting in the black box problem, would not be used by institutions.
Amount of Data: Neural networks require significantly more data than traditional ML algorithms. The thousands or millions of labeled data points require time to prepare and make ready for training the model. Additionally, the computational resources required for a program increases along with the amount of data utilized in a ML algorithm.
Computing Power: Semiconductor technology will be covered in a Primer on Semiconductors; however, a brief overview is important for this discussion on AI. The speed of training, network architecture, and quantity of data that can be utilized depends on the program's computing resources. There are two different types of resources: computational (processing) and memory.
- Computational / Processing: Processing power enables the "learning". The more power the program has, the faster it can complete each request (mathematical calculation). So, the greater amount of processing power enables faster training, all else equal.
- Central Processing Units (CPUs): The CPU is the "brain" and core component of any device. It functions by taking instructions from a program or application then performs a calculation. Each calculation has to be done sequentially. The quantity of CPU cores in the processing unit dictates how quickly complex calculations can be performed. Each core performs one task at a time. So, the more cores a unit has, the more efficient it is. The processing power of each CPU is dependent on the number of transistors on the chip. The CPU can be thought of as the taskmaster of the entire system, coordinating a wide range of general-purpose computing tasks.
- Graphics Processing Units (GPUs): The industry's emergence from the AI Winter post-2012 was enabled by the realization that leveraging GPUs could accelerate the processing speed of algorithms (see below). Mainstream knowledge of modern GPUs revolves around their efficiency at manipulating computer graphics and image processing. However, the power of GPUs lies in their highly parallel structure. GPUs perform a narrower range of more specialized tasks than CPUs. Using the power of parallelism, a GPU can complete more work in the same amount of time as compared to a CPU. This is why GPUs are critical for AI programs; they can quickly process large blocks of data simultaneously to train an algorithm.
- Memory: Random-access Memory ("RAM") is also a critical component of the overall computing architecture, as it allows for more training data to be stored at a time.
The progress of neural networks and overall AI is dependent on the continued advancement in semiconductor technology. However, the industry is running into physical constraints, which is limiting the progress of chip processing speeds. The takeaway is that the advancements in chip technology will require a breakthrough if AI progress is to maintain its current rapid pace.
The Issue of Computing Power Today
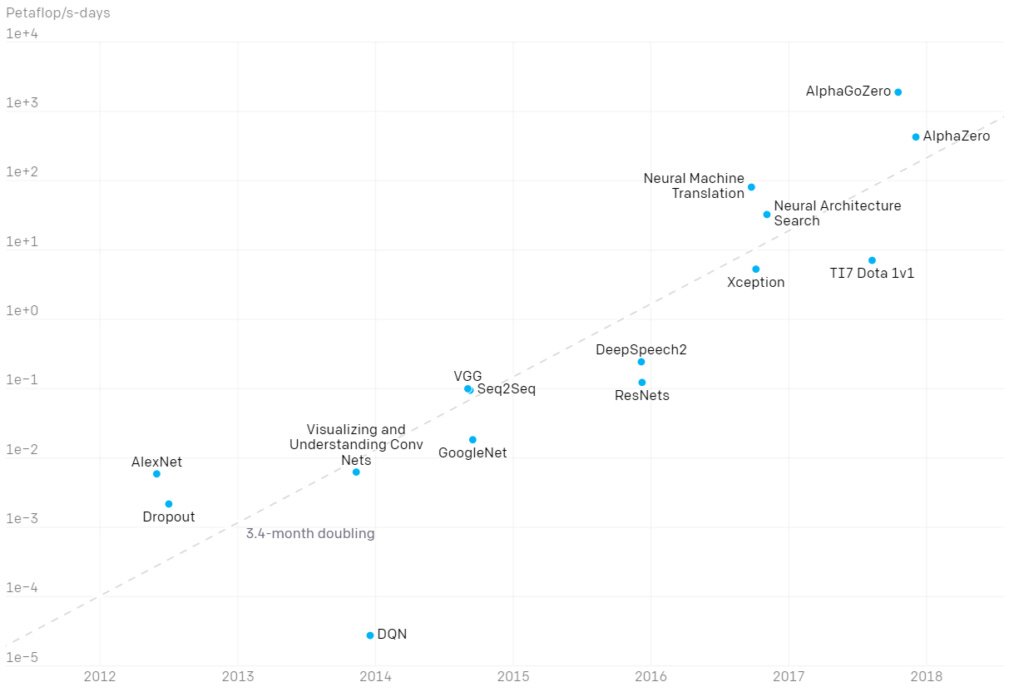
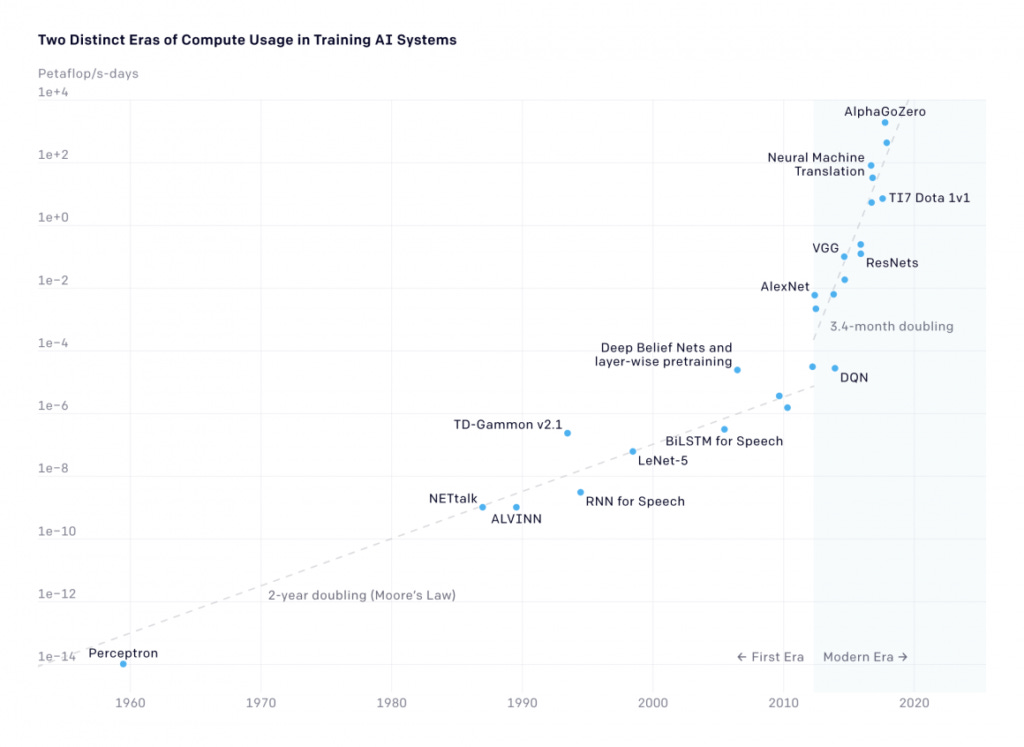
According to an analysis published by OpenAI in 2018, the required computing power for training AI programs used to follow Moore’s Law. However, since 2012, computing power used in the largest AI training programs has increased exponentially. As opposed to the roughly 2-year cycle of doubling computer processing power (Moore's Law), computing power used for AI is doubling ever 3.4 months. It follows that the progress of future AI technologies may be limited if the advancements in computing power lags. Debate remains around if Moore's Law still holds; however, most experts anticipate Moore's Law will end within the next five years or so.
We’re releasing an analysis showing that since 2012, the amount of compute used in the largest AI training runs has been increasing exponentially with a 3.4-month doubling time (by comparison, Moore’s Law had a 2-year doubling period). Since 2012, this metric has grown by more than 300,000x (a 2-year doubling period would yield only a 7x increase). Improvements in compute have been a key component of AI progress, so as long as this trend continues, it’s worth preparing for the implications of systems far outside today’s capabilities.
https://openai.com/blog/ai-and-compute/
A review of how CPUs and GPUs work together to optimize algorithm processing speeds will be covered in more detail in the semiconductor Primer. A brief understanding of this relationship is helpful to understand how the AI industry has been able to accelerate since 2012. A CPU works with a GPU to increase the throughput of data and the number of concurrent calculations within an application. The GPU complements CPU architecture by allowing repetitive calculations within an application to be run in parallel while the main program continues to run on the CPU.
Analogy: A CPU is the checkout register at a store; it is designed to 1) identify the product type, 2) identify the quantity of the item, 3) identify the price of each item, 4) calculate total price based on quantity and price, 5) add the price of all items together, 6) print a receipt that summarizes the entire process. The task is checking out a customer. What if there are 100,000 items in the customer's cart? This would take the CPU a significant amount of time to loop through the first four steps for each item and then complete steps 5 and 6. That's where GPUs come in. One GPU could specialize in bagged apples, another could specialize in organic almonds, etc. ad infinitum. Instead of the cashier having to 1) count how many apples are in each bag, 2) look up the product code in the system, 3) type in the number of apples in the bag, 4) locate the price of the product, 5) multiply count * price, then 6) record it; the bagged apples GPU is programmed to do all of this in one step, vastly accelerating the processing of bagged apples. Each GPU performs this function for each item in the cart that it specializes in, feeds the information back to the CPU, and the CPU collates all the information from all the GPUs to perform steps 5 and 6. GPUs working with the CPU accelerates the entire process and allows for more items to be checked out for a given customer or in any given day!
Seifel Capital Analogy
Quantum Computing- Possible Saving Grace
The architecture and math behind The AI industry may avoid the issue of Moore's Law ending thanks to the rise of quantum computing. Google released the results of its quantum supremacy experiment using Sycamore, a quantum computer, one year ago. Google explained that Sycamore performed the target computation in 200 seconds. The same computation would have taken the world’s fastest supercomputer 10,000 years to produce a similar output (IBM argued Google miscalculated the differential, which was 2.5 days vs. 10,000 years). Relatively, 1.58 MILLION times vs. 1.46 MILLION times faster than the leading supercomputer seems to be splitting hairs here. The takeaway is the computing power potential of quantum computing could allow AI to continue its progression (or speed it up...).
Current State of Neural Networks and Use Cases
Current State of Neural Networks
AlexNet
Neural networks have become the focus of AI advancement since GPUs started to be utilized to run programs. The realization came in 2012 when Alex Krizhevsky developed a Convolutional Neural Network ("CNN") called AlexNet to compete in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) The ILSVRC is a competition which evaluates algorithms for object detection and image classification at large scale. The results of the competition can be used to measure the progress of the AI industry. The competition was established in 2005 and a lot of progress had been made once the 2010s rolled around. This progress resulted in a top 5 error rate of ~25%, meaning the best programs were correctly classifying only 3 out every 4 images. In 2012 when AlexNet won the competition, the second place error rate was 26.2%. AlexNet achieved an error rate of only 15.3%; its accuracy was almost 11% better than second place. AlexNet's use of GPUs, CNN, and a new activation function (ReLU) that improved the efficiency of the program was an inflection point that catalyzed the industry's boom.
OpenAI
OpenAI is one of the world's leading AI research laboratory's despite being just four years old. It was co-founded by two relatively well known guys: Sam Altman and Elon Musk. Its objective is to safely and responsibly develop artificial general intelligence ("AGI"), meaning a machine with the learning and reasoning powers of a human mind (recall from Part I). OpenAI continues to push the industry forward, most recently with its new language generator, GPT-3.
GPT-3 is the most powerful language model ever. Its predecessor, GPT-2, released last year, was already able to spit out convincing streams of text in a range of different styles when prompted with an opening sentence. But GPT-3 is a big leap forward. The model has 175 billion parameters (the values that a neural network tries to optimize during training), compared with GPT-2’s already vast 1.5 billion. And with language models, size really does matter.
MIT Technology Review, July 20, 2020
OpenAI was able to increase the number of model parameters by 117x over the course of one year. GPT-3 can generate any kind of text, including computer code, in human-like form on demand. This remarkable achievement still leaves us far from AGI. Despite the human-like output and versatility of the program, it can still produce some nonsensical and / or robotic-like responses. This means GPT-3 would still fail the Turing Test. Even Sam Altman said this is just an early glimpse at true AGI. The 175B parameters makes GPT-3 the largest neural network ever created. To wrap up this overview of the current state of neural networks, let's explore the features and metrics discussed in this Primer applied to GPT-3:
Total Parameters: 175B (although, comes in 8 different sizes)
Layers: 96
Batch Size: 3.2MM
Learning Rate: 0.6 * 10-4 (0.0006)
FLOPS of Computing for Training: 3.14 * 1023 / 3,140 Petaflop/s-days / 0.314 yottaFLOPS
Total Compute Cycles Required: Equivalent of running one thousandtrillion floating-point operations per second per day for 3,140 days (~8.6 years)
Memory Required: 4 Bytes per Parameter * 175B Parameters = 700GB of Memory
~14.6x more memory required than max on a single GPU (48GB of Quadro RTX 8000)

The industry's progress is extremely impressive. But I'll end this section with one final note: models are under development that use more than a trillion parameters!
Neural Network (Business) Use Cases
Focusing on the business use cases of neural networks, you may be surprised by how prevalent they are in our every day lives. Most neural networks are currently used by businesses to automate menial or time-consuming tasks. Essentially the aim is to increase capital efficiency, both human and financial. Some of the common use cases are:
Image Recognition: Social networks utilize neural networks to automatically tag friends' faces in pictures uploaded to the website (i.e. Facebook)
Video Recommendations: Video streaming sites, such as YouTube utilize neural networks to suggest videos to watch next based on user watching habits, or similar user habits.
Self-Driving Cars: Tesla is usural networks to train sensors for the autopilot function in cars to ‘see’ what’s happening around it and react appropriately.
Natural Language Processing / Understanding ("NLP"): Voice recognition software on mobile and home assistants, such as Amazon's Alexa, is an example of neural network programs.
Loan / Credit Card Underwriting: Banks provide loans to users based on different factors. Neural networks are utilized to underwrite a loan and decide whether to approve or reject the loan application. Some credit card companies have begun to use neural networks to accept or reject applications, as well.
Neural networks are already being utilized by companies in a variety of industries to improve operational and capital efficiencies, as well as the consumer experience. Facebook utilizes neural networks for their facial recognition application, YouTube for their video recommendation capabilities, Tesla for training autopilot functionality, among many others. The utilization of neural networks and other AI programs will only increase in prevalence with the advancement of computing capabilities and overall comfort in adoption. The AI industry has been advancing at an exponential rate since 2012 due to the advancements in neural network technology. I personally can't wait to see what the future holds and the positive impact this technology will have on society.
