
Artificial Intelligence (AI) Primer - Part II
Part II: Machine Learning and Supervised Learning

Hi Everyone,
I sent out this newsletter through my website, but my understanding is there have been a lot of issues with that transition. As such, I will be resending my AI Primer Parts II and III through this substack. I may have to continue distributing through this medium until certain technical issues get sorted out. It seems drafting the newsletters through the website and pasting in here solves the formatting issue I referenced. Apologies for the duplicate emails for Parts II and III, please ignore if so!
You can check out my new website here if you haven’t seen it yet. Would love to hear your thoughts!
Please make sure to share this newsletter, share this post, or subscribe (if you have not already) if you like the content! You can use the buttons here to do so:
DISCLAIMER:
All investment strategies and investments involve risk of loss. Nothing contained in this website should be construed as investment advice. Any reference to an investment's past or potential performance is not, and should not be construed as, a recommendation or as a guarantee of any specific outcome or profit.
With that, please enjoy Part II of the primer on Artificial Intelligence!
Artificial Intelligence Primer, Part II: Machine Learning and Supervised Learning

Definitions
Please refer to this section for definition of terms that are not described in the body of the Primer:
Feature: A category or type of input data that is fed into the model to help it learn. It is the independent (x) variable in a simple linear regression.
For example, the Features of a model to predict the winning percentage of a baseball team may be 1) payroll and 2) prior year winning %. Note that the input data is each instance of the Features (i.e. payroll and prior year winning %) that are fed into the model.
Hyperplane: A subspace whose dimension is one less than that of its ambient space. A line is a hyperplane for a 2D graph.
Label: What is being predicted in the model. It is the dependent (y) variable in a simple linear regression.
Linear Separability: A key concept in ML that determines if different data points can be separated by a line.
Overfitting: Occurs when ML algorithm learns input and output data too exactly, making it treat noise in the data as true parameters and identifies spontaneous patterns / relationships as legitimate. The machine creates a model that is too complex.
Parameter: A model parameter is a configuration variable that is internal to the model and whose value can be estimated from data. The weights in an artificial neural network are parameters.
Underfitting: Occurs when the machine fails to identify actual patterns and relationships, treating true parameters as noise. The machine creates a model that isn’t complex enough to describe the data.
Machine Learning
What is Machine Learning (“ML”)?
As discussed in Part I of this AI Primer, ML is a subfield and the most common application of AI. ML allows machines to access data themselves, learn from this data, and perform tasks; this is done through learning algorithms and statistical models. It enables machines to automatically learn and improve from experience without being explicitly programmed. ML focuses on the development of computer programs that can access data and use it for their own learning.
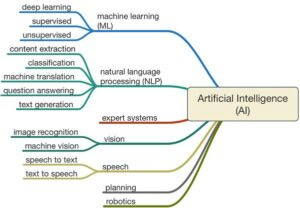
There are four types of Machine Learning: 1) Reinforcement Learning, 2) Unsupervised Learning, 3) Semi-supervised Learning, and 4) Supervised Learning. Part II of this Primer will cover Supervised Learning, but first it is important to understand some key aspects of ML.
Understanding Machine Learning
We can use basic algebra to better understand how Machine Learning works with the equation Y = f(X). ML algorithms are designed to learn a target function (f) that best matches input variables (X) to an output variable (Y). Referencing the definitions above, we know that the input variables are features (independent variables) and output variables are labels (dependent variables).
In other words, the goal of ML is to create a learning mechanism that make predictions in the future (Y) given new examples of input variables (X).
Since algorithms are like babies, they know nothing when they are initially created, it doesn’t know what the function (f) looks like or it’s form from the start (if it did, it wouldn’t need to learn!)
However, learning a function from data is a difficult problem, which makes these models subject to error. So, we must contemplate an error (e) numerical constant that is independent of the input data (X) in our final ML formula: Y = f(X) + e.
ML is most commonly used for predictive modeling / analytics to make the most accurate predictions as possible. The goal is for the model to learn how to crosswalk Y=f(X) to make predictions of Y based on a new X.
The Machine Learning Process

Data Collection: Collect vast amounts of data (labelled for Supervised Learning; not labelled for Unsupervised Learning) that the algorithm will learn from.
Data Preparation: The raw data needs to be “cleaned” before it is used. Cleaning usually requires normalizing the data, removing duplicates, and/or evaluating for errors or biases. The goal is to optimally format the data and extract important features. Data Scientists use visualization to look for patterns and outliers in the data; to see if the right data has been collected or if data is missing.
Model Selection: There are many different ML models to choose from, depending on the problem you are trying to solve. Commonly used machine learning algorithms include linear regression, logistic regression, decision trees, K-means, principal component analysis (PCA), Support Vector Machines (SVM), Naïve Bayes, Random Forest and Neural Networks. Key factors to keep in mind is how much preparation the model requires, how accurate it is, and how scalable the model is. Complexity and quality are not necessarily correlated, as too much complexity can make it difficult to optimize or explain the model.
Training: Also known as the fitting stage, this is where all the magic happens. The Machine Learning algorithm learns by ingesting the training data that has been collected and prepared, then incrementally improve its predictions by adjusting the model with each training step. A training step is one cycle of updating the weights and biases of a model (explained below). The amount of data required for a ML algorithm is proportional to the number of variables used in the model.
Evaluation: Evaluation requires testing the model with a mutually exclusive dataset (“validation data”) to see how well it performs.
Parameter Tuning: The original model parameters need to be tested with more training data to improve the AI algorithm after the Evaluation stage. Each cycle of improving the algorithm by adjusting the parameters is known as a training cycle.
Prediction: The final step of developing an ML algorithm is testing the algorithm to see how good it is at answering questions through predictions.
How to Determine the Best ML Model
To conclude Part II of this AI Primer, I wanted to explain how to know which model should be chosen for an analysis. The four quantitative metrics we will use are: 1) Accuracy, 2) Precision, 3) Recall, and 4) F1. To illustrate these metrics, we will use a confusion matrix. A confusion matrix is a table that is used to describe the performance of a classification model in Supervised Learning.
ich the output of the model correctly predicts what the output should be. Simply, how many predictions did the model get right? Formulaically, it is the total number of correct outputs / the total number of outputs.
In the image above: Accuracy = (True Negative + True Positive) / Total Observations = (35+50) / 100 = 85%
Precision: How close two or more measurements (outputs) are to each other. Precision tells us how much a program should be trusted when it says it has found something. If the model tells us the result is a positive, we are expecting a positive. Precision should be used to determine which model to use when there is a high cost of a False Positive (i.e. Type I Error). For instance, a pregnancy test that comes back positive when someone is not actually pregnant.
Precision = True Positive / (True Positive + False Positive) = 50 / (50+10) = 83.3%
Precision matrix: True Positive + False Positive = Total Predicted Positive
Recall: Recall measures how much your program can find of the thing you are looking for. Recall is the metric used to select the best model when there is a high cost associated with a False Negative (i.e. Type II error). For instance, a pregnancy test coming back negative when the patient is actually pregnant. Think about it as, of all the test results that were actually positive, how many did the model identify correctly as positive?
Recall = True Positive / (True Positive + False Negative) = True Positive (predicted) / Total Actual Positive >> 50 / (50+5) = 90.9%
Recall Matrix: True Positive + False Negative = Actual Positive
F1 Score: F1 is a function of Precision and Recall, which can be used to strike a balance between the two measures.

To understand the difference between F1 Score and Accuracy, let’s analyze business cases. As seen above, Accuracy can be largely attributed to a large number of True Negatives, which is not a focus in most business cases. However, False Negatives and False Positives usually have business costs. So, F1 Score is a better measure than Accuracy when striking a balance between Precision and Recalland there is an uneven class distribution.
F1 Score = 2 * [(83.3% * 90.9%)/(83.3% + 90.9%)] = 87.0%
Supervised Learning
What is Supervised Learning (“SL”)?
I provided a brief overview of Supervised Learning in Part I of this AI Primer, but let’s dive deeper. Supervised learning is the most common type of ML today and it can be found in many aspects of our lives, even if you are not aware of it. Like all ML algorithms, supervised learning is based on training. The system ingests large amounts of data during its training phase, which tell the system what output should be generated from each specific input value. The trained model is then given test data to verify the result of the training and measure the accuracy.
To be a little more specific, Supervised Learning is an approach to creating AI where a program is given pairs of labelled input data and output data (the “training data”) during the learning process to teach the program how it should behave (hence “supervised”). Think about SL as a program that is given a test and the answer key, so that it knows the right answer to every question.
With these two data sets, the model is trained until it can detect the underlying patterns and relationships within the data and produce the correct outputs for the given inputs. The algorithm quality is then tested with a new and different data set (the “test data” or “validation data”) that is mutually exclusive from the training data. This last step ensures that the program is actually learning instead of just memorizing answers from the training data.
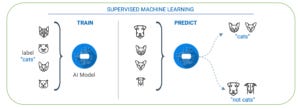
Generalization is the ability of algorithms to adapt to new inputs and make predictions. The goal of training the program is to maximize generalization so that supervised model defines the real ‘general’ underlying relationship. Providing too much training data to the model causes overfitting (definition above) and the model would be unable to adapt to new, previously unseen inputs. Alternatively, providing too little data leads to underfitting.
The output from a supervised Machine Learning model could be a real-world scalar (in other words, numerical). These models are known as Regression. A second type of output an ML algorithm can generate is a category from a finite set (i.e. tall, medium, short). In this case, the model is deciding how to classify the input and is appropriately defined as Classification.
Types of Problems Solved with SL
There are generally two types of problems that can be solved, or “subfields”, using Supervised Learning algorithms: Regression and Classification.
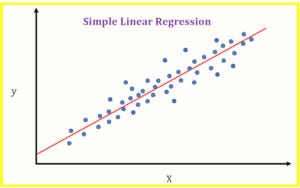
Regression: Regression is a ML method used for numerical data. The goal of regression is to model the relationship between a certain number of features (independent variables) and a continuoustarget variable (dependent variables). So, we can define a regression problem as one in which the output (dependent) variable is a real or continuous value (i.e. “salary” or “weight”). While there are many different models that can be used, the most basic form is the linear regression. A linear regression tries to fit the algorithm data with the best hyperplane that goes through the data points formed by input and output data. The output data (dependent variable) is plotted along the y-axis and the input data (independent variables) is plotted along the x-axis. You can learn more about linear regression here. The two most common types of regression models in ML are:
Least Squares (or Ordinary Least Squares [“OLS”]): The process requires drawing a line through the data points fed into the model and measuring the distance from each data point to the line. The distance from a data point to the line is called the error. The error for all data points in the set is added together for a sum total for the line. This process is repeated numerous times until the line with the lowest total error is found. The “least” part of the name is evident, the “squares” aspect refers to the fact that the errors are all squared before added together so that negative errors don’t cancel out positive ones.
This regression model is appropriate when a linear relationship exists. This does not mean the data has to be two dimensional (a line is used); hyperplanes are used for higher dimensions (i.e., more variables).
Least squares is a common method due to the less intensive computing requirements, and thus lower costs. However, it is not a useful tool for non-linear relationships.
k-Nearest Neighbors (“KNN”) Regression: The k-nearest neighbors approach can be used for Regression but it is more closely associated with Classification. KNN Regression outputs the average of the nearest points depending on the number of points the user decides to apply. As an example, a feature that uses three neighbors will use the three closest points (based on input), and the corresponding output (prediction) is the average of those data points.

Examples of regression problems include predicting someone’s age, predicting if a stock price will increase tomorrow, and predicting how many people will show up to a store opening.
The difference between Classification (explained below) and Regression is that a Regression analysis outputs a number, while a Classification analysis outputs a “class”. Both SL methods can be utilized for very complex tasks involving unstructured data (i.e. speech and audio).
Classification: Classification attempts to assign data points to a specific category based on its distinct features or characteristics. Classification organizes similar data points into different sections in order to classify them. While regression models predict continues values, classification models predict discrete values. To be clear, the output of a classification model is a category i.e. “blue” vs. “green” or “tall” vs. “short”. The goal of the ML program is to find the rules that explain how the different data points should be separated or grouped based on the inputs.
The algorithms use data and outputs to discover rules that linearly separate data points. Classification tries to find the best way to separate data points with a line/plane.
Decision Lines / Boundaries: The lines drawn between classes.
Decision Surface: The area that is chosen to define a class. So, the decision surface defines that if a data point falls within its boundaries, it will be assigned a certain class.
There are generally four main types of Classification tasks:
Binary Classification: Classification tasks that have two class labels (i.e. spam filters).
Multi-Class Classification: Classification tasks that have more than two class labels (i.e. face classifications).
Multi-Label Classification: Classification tasks that have two or more class labels, where one or more class labels may be predicted for each example (i.e. being able to identify buildings, cars, and people in a photo).
Imbalanced Classification: Classification tasks where the amount of examples in each class is not equally distributed. These are typically binary classification tasks, but there are more examples of one example than the other (i.e. fraud detection).
Some of the most common Classification methods are:
Linear Support Vector Machines (“SVMs”): SVMs are similar to OLS regressions in the sense that SVMs look for a line that fits between the two (or more) classes, then expand that line as wide as possible. The line that can expand the farthest is considered the decision line. In a graph, points on one side of the line are Class A and points on the other side are Class B, similar to the example of chimps and humans below. SVM takes many line guesses and tries to widen each. The line that can be widened the most before it touches a data point is considered the best classifier. You can think about it as the decision line that has the greatest buffer between data points and the decision criteria. Now, when a height and weight combination is fed into the algorithm, the prediction of chimp vs. human will be based on what side of the line the data point falls.
Non-Linear SVMs: When lines don’t conform to the data, the model can draw circles out from data points and then put them together to get the decision line that offers the widest buffer between Class A and Class B data points.
Linear SVM using Weight and Height Features; the Green Line is the Best Classifier
Decision Tree Classifiers (“DTCs”): Decision trees recursively separate data points into groups called nodes. Each node is a subset of the node above it. The accuracy of predictions should improve the further down the branches the program goes. A drawback of DTCs are its tendency to overfit the training data (i.e. high accuracy on the training data, but low accuracy on the test data).
Pure nodes are when a branch of the DTC terminates because all the data points in the node are in the same class (it can’t be broken down any further). Conversely, if the node contains samples of more than one class, it could be split further. The model complexity is related to how defined the classes are, or how many times the data is split.
The maximum number of nodes and depth are the two parameters commonly adjusted when trying to train the best DTC.
Depth: How many times the DTC should split up the data. For example, if the maximum depth is set to four the DTC will only split subsets four times. The splitting stops even if the ending nodes are not pure. The DTC does, however, splits the data to achieve the highest purity in the end nodes. Adjusting maximum depth can reduce overfitting.
Maximum Number of Nodes: The number of total nodes in the DTC. If this is set to six, there can only be six total subsets. This could work a variety of ways. It could occur with a depth of one, in which the original set is split into six subsets immediately. If the depth was set to two, like in the example below, the original node splits into two subsets, and each of those two subsets is split into two further subsets.
DTC with a Depth of 2 and 6 Max # of Nodes
Random Forests Classifiers (“RFCs”): The DTCs discussed above can created overfitted models easily. A method to mitigate this potential is to use a set of trees, or a forest. These forests are named random forest classifiers, which are a collection of DTCs with randomly selected data from the training set. The concept of RFCs is based on the law of large numbers, meaning that having more samples is often better for training a model.
There are more parameters used in RFCs than DTCs: 1) maximum depth, 2) maximum nodes, 3) minimum samples per node, 4) other parameters for each tree, and 5) how many trees and features (input variables) to use. The algorithm builds trees using different subsets of the training data set in order to avoid bias in the model.
Data scientists can prevent certain features from dominating every tree by setting the maximum number of features to a lower figure than the total number of features in the training data. This makes the forest more reliable and diverse. The final output is based on the combination of the tree outputs. So, if there are 15 trees in the forest and 10 trees predict Class A and 5 predict Class B, the RFC will call that data point Class A.
There are two primary drawbacks of RFCs: 1) high level of required processing power (however, utilized GPUs to run parallel processes mitigates this burden) and 2) the black box problem. The black box problem is something that will be discussed further in a deep dive of neural networks. Essentially, the black box problem arises when the computer scientist (human) can’t determine why the model reached its decision. As one could imagine, this happens frequently in RFCs because there are so many DTCs.
Random forest classifier example
Neural Networks: The creation of Supervised Learning was mostly inspired by our human brains, specifically the billions of cells in the brain called neurons. Today, scientists develop programs to behave like the human brain, called Neural Networks. While Neural Networks are powerful models and quite efficient, their implementations are complex also suffer from the black box problem. Neural Networks are arguably the most popular of AI topics so we will be covering this method more in depth in Part III.
Neural networks are layered sets of nodes, where input nodes send signals to nodes in a hidden layer (or layers), which then send signals to a final output. Every input node is connected to every hidden node, and every connection has its own weight. This means that each Feature can influence each hidden node differently, based on its weight between 0 and 1.
If the hidden node reaches its threshold, it propagates forward a signal. This could be to another hidden layer, or it could be to the output.

Simple diagram of a Neural Network
There are three disadvantages of Neural Networks: 1) requires large amounts of data, 2) uses a lot of memory, and 3) the black box problem. These will be covered more in Part III, but one thing to realize is that the complexity, and thus degree of the black box problem, is related to the number of hidden layers and nodes in the program.
Conclusion
In Part II of this AI Primer, we reviewed the concept of Machine Learning in a little more detail and then developed a deeper understanding of Supervised Learning ("SL"). Specifically, we reviewed the two different types of SL (Regression and Classification) and the different types of models used for each. In Part III of this Primer next week, we will develop an extensive understanding of the most common type of SL, Neural Networks. After that, we will start diving into use cases, applications, and what it means for future industry.
Best of luck,
Christopher