
Artificial Intelligence (AI) Primer - Part IV
A Framework for Analyzing Artificial Intelligence and Machine Learning

Hi All,
This week’s post took a lot of time researching and developing what I believe is the only framework for evaluating the impact of AI / ML on a company. While almost every company claims to be using AI or ML of some sort, how can you know it is legitimate? If it is legitimate, how do you measure the level of competitive advantage it provides? These are the questions I tackle and answer in this final part of my Primer on Artificial Intelligence. You can read this post on my website and the other parts of the Primer on my site as well. I’m looking forward to hearing your thoughts on this framework.
Please make sure to share this newsletter, share this post, or subscribe (if you have not already) if you like the content! You can use the buttons here to do so:
DISCLAIMER:
All investment strategies and investments involve risk of loss. Nothing contained in this website should be construed as investment advice. Any reference to an investment's past or potential performance is not, and should not be construed as, a recommendation or as a guarantee of any specific outcome or profit.
Artificial Intelligence Primer, Part IV: A Framework for Analyzing Artificial Intelligence and Machine Learning

Executive Summary
Artificial Intelligence ("AI") has seemingly become a buzzword utilized by companies and market participants in an attempt to indicate a superior business or technology. This pseudo-intellectual approach to supporting an investment thesis or pitching a company's prospects is dangerous at best. Not only is the term AI misused quite frequently, but there seems to be a widespread misunderstanding or conflation of what it actually means. AI is still far away from achieving human intelligence, but it can provide a company with a sustainable competitive advantage.
In this paper I endeavor to provide a framework to analyze how a company is using AI, what kind of AI is being used, and how valuable it may be to the company's business prospects. According to MIT Technology Review, 97% of the companies they surveyed are expected to have deployed AI usage in the organization by the end of 2020. Some industries are utilizing AI more than others, evidenced by the dispersion in AI penetration amongst firms in the graphic below. A consistent theme among respondents was the gradual, methodical, and iterative nature of AI deployment. So, although AI may be widely adopted, it has not yet become pervasive throughout organizations. These macro trends are important to keep in mind.
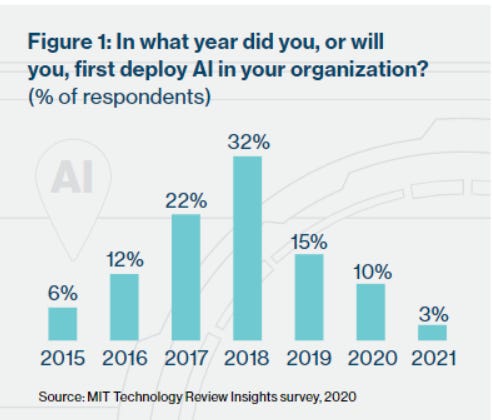
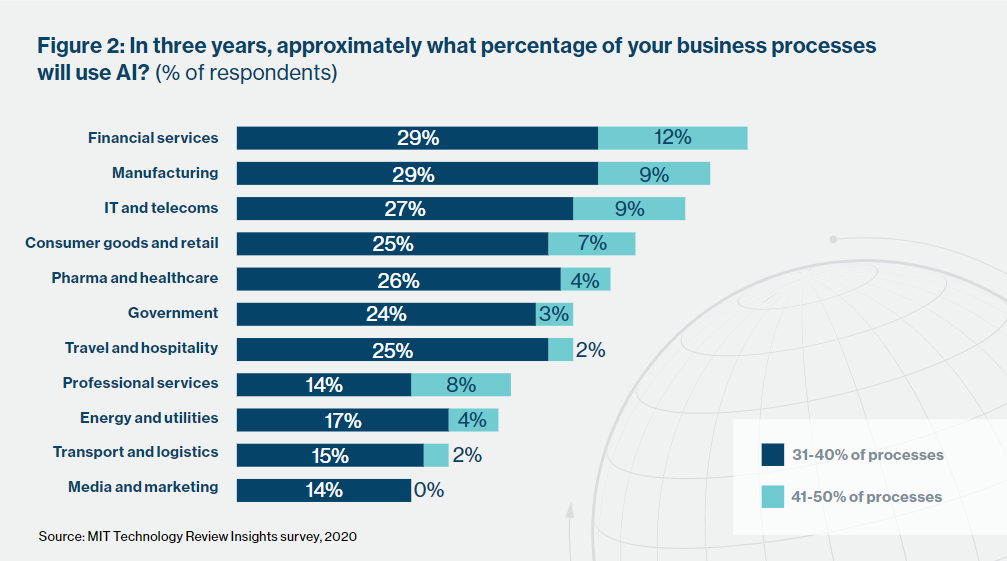
Introduction
To conclude this primer on Artificial Intelligence ("AI") we will review how companies are utilizing AI and/or Machine Learning ("ML"). Specifically, I want to focus on how to identify the value created by companies utilizing these technologies. After all, this primer is not helpful for your investing process unless I can provide actionable insights.
Artificial Intelligence is a commonly misused phrase in the sense that there is often a failure to disintegrate its sub-fields. All Machine Learning is Artificial Intelligence, but not all Artificial Intelligence is Machine Learning. This is an important distinction as we move forward. So, let's revisit some key definitions in order to build a foundation for understanding the practical value of each. The field of AI can be visualized as such:
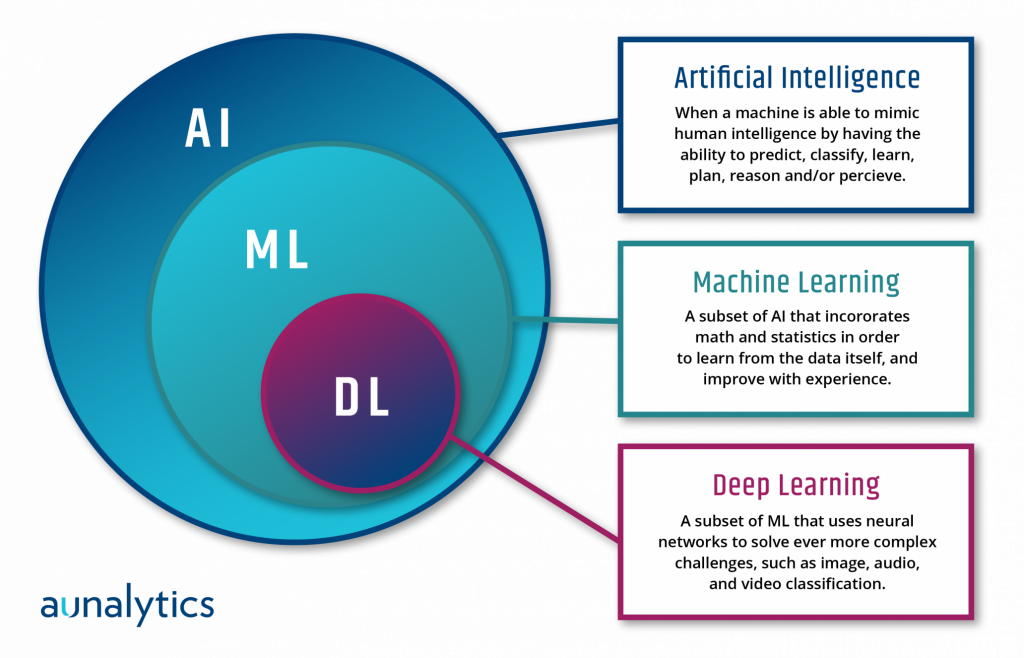
Definitions
Artificial Intelligence: Broad discipline and field of creating “intelligent” machines. Essentially, it is a set of algorithms and techniques to try to mimic human intelligence. A machine has AI if it can 1) interpret data, 2) potentially learn from the data, and 3) apply that acquired knowledge to adapt and achieve specific outcomes.
By definition, I would argue that Microsoft Excel is a form of AI.
Machine Learning: Machines can access data themselves, learn from this data, and perform tasks; this is done through learning algorithms and statistical models. It enables machines to automatically learn and improve from experience without being explicitly programmed.
Deep Learning ("DL"): This is a sub-set of Machine Learning. The utilization of many multi-layered neural networks to solve complex problems, i.e. image recognition.
Clarifying the Differences
What I endeavor to do in this article is help you identify what aspect of AI is being utilized and how to understand the value creation capabilities of that system. To do so and avoid any confusion, I want to create a name for everything that is considered AI but is not as complex as ML. Let's call these programs Basic Artificial Intelligence ("BAI"). Yes, I just made up this term. My article, my rules! Most of this article will be comparing BAI to ML.
AI is the broad category which includes all machine learning and deep learning. Meanwhile, all deep learning is a sub-segment of machine learning. So, think about it this way: AI is the parent company, ML is a subsidiary, and DL is a division within the ML subsidiary. As you will see, ML is the most valuable subsidiary of AI, and DL is the most valuable division of ML.
We know that AI refers to any type of machine with intelligence. The Oxford Dictionary defines intelligence as the ability to acquire and apply knowledge and skills. So at a fundamental level, we can think of intelligent machines as being capable of solving a specific problem with the knowledge and skills embedded in its algorithm. So, our definition of Basic Artificial Intelligence is any program or machine that solves a specific problem.
But what if we need to do more than solve a specific problem? Or better yet, what if we don't even know the problem we are trying to solve?! Machine Learning takes BAI to another level, as these programs are similar to human intelligence and somewhat "self-aware". The easy way to differentiate between ML and BAI is that an ML program learns by itself. Just as humans learn as they consume more information, a ML algorithm gets better at learning as it processes more data.
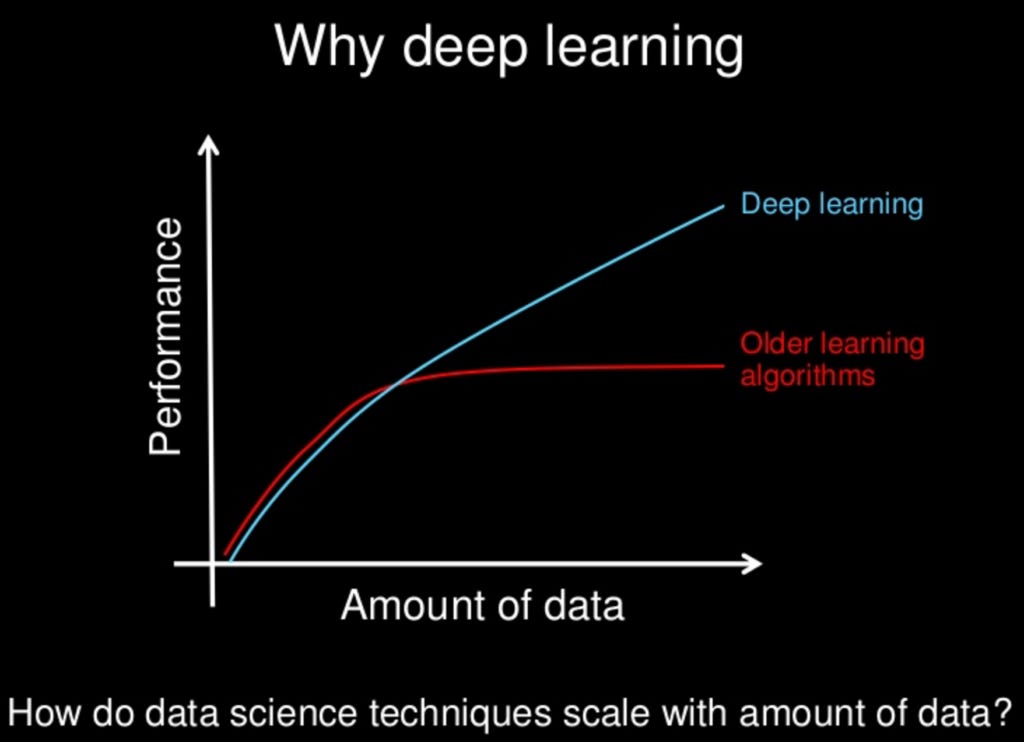
Deep Learning takes Machine Learning a step further by using deep neural networks (see more in Part III of this Primer). While I won't go back into detail on the topic, it is important to know that DL typically provides the best results of any type of Machine Learning program.
Before we get into the heart of the matter, I wanted to thank Tyler Lastovich for his contribution to this article. Tyler has been a great sounding board to bounce ideas off of, provided some helpful graphics, and has a remarkable command of the AI landscape given his vast experience. Thanks Tyler! He is creating a Machine Learning driven investing platform to help the every day person compete with Wall Street. You can sign up for Invest Like the Rest today!
Fields and Use Cases: BAI vs. ML
Let's expand on the visual above to understand some of the tangible problems each BAI and ML can solve for, and some corresponding use cases.
Basic Artificial Intelligence Problems and Use Cases
Search and Optimization: These problems are solved by an algorithm looking for a solution which is best among others. The process entails searching through the space of possible solutions. In Engineering and Mathematics, this process is thought of as optimization - to find the best solution or an optimal solution for a problem.
One example that I have become intrigued by is the travelling salesman problem, which asks: "Given a list of cities and the distances between each pair of cities, what is the shortest possible route that visits each city exactly once and returns to the origin city?"
This example illustrates one such use case for modern companies: logistics.
Constraint Satisfaction: These problems are mathematical questions defined as a set of objects whose state must satisfy a number of constraints or limitations. Essentially, when given certain variables and certain constraints, the algorithm finds a solution for the variables that fit within (meet) the stated constraints.
Believe it or not, Sudoku and Crossword Puzzles are constraint satisfaction problems!
Modern companies can use constraint satisfaction problem solving algorithms for resource allocation decisions.
Logical Reasoning: There are many types of logical reasoning problems (e.g. deductive, inductive, abductive, etc.) but generally, logical reasoning problems require the machine to figure out how to do something when it has not been told explicitly how to do it. Programs accomplish this by drawing conclusions from premises using a rule of inference.
Example (please recognize the satire): Fact 1: All stocks go up; Fact 2: Anacott Steel is a stock. Then we can ask, in what direction will Anacott Steel move tomorrow? Answer: Up.
Companies can use logical reasoning BAI to apply coupon codes to orders.
Probabilistic Reasoning: This method combines the logical reasoning above with probabilities for situations when there is uncertainty. Logical These programs are a way to represent knowledge where the concept of probability is applied to indicate the uncertainty in knowledge. This method is used when either 1) errors are known to occur in the experiment, 2) the user is uncertain of the predicates (statements about the subject), or 3) there are too many predicates to list.
For brevity, the applications would be similar to the logical reasoning examples above but in situations containing uncertainty.
Machine Learning Use Cases
Recall there are three main learning paradigms: unsupervised learning, supervised learning, and reinforcement learning that was discussed in Part I.
Deep Learning: Deep learning consists of training many-layered neural networks with vast quantities of labeled data. The program can then learn on its own through backpropagation algorithms that adjust model parameters to arrive at more accurate conclusions. Taken a step further, deep learning models have evolved to a point in which the models can figure out the features of a data-set itself (i.e. convolutional neural networks ["CNN"])
The most exciting advancements in ML and broader AI is from deep learning. Examples include autonomous driving, medical research, language and speech recognition, etc.
Natural Language Processing (NLP): Depending on who you ask, NLP is its own segment of AI, separate and apart from ML. However, NLP and ML are undoubtedly used together, so I will include it in this section. NLP deals with how computers understand and translate human language. It enables machines to make sense of written or spoken text and perform tasks like translation, keyword extraction, topic classification, and more.
Siri, Alexa, chatbots, Google translate, and more all use NLP.
Association Rule Learning: These programs are used to find correlations and co-occurrences (relationships) between data sets. They are especially helpful to explain patterns in data from independent data locations like relational databases and transactional databases.
These programs are already being used commercially. Some examples include assisting doctors with medical diagnoses, retail companies can identify co-occurrences of purchases to see what products are bought together, and Netflix / Spotify / YouTube recommendation engines.
Decision Trees: Decision Trees are a form of Supervised Learning that can solve both types of learning problems: classifications and regressions. These models can be used to predict the class or value of the target variable by learning simple decision rules inferred from prior data or just the training data. Decision Trees are used commercially to handle non-linear data sets.
Decision trees have been around for quite a while, but the quality of these programs are improving. Think about buying a plane ticket online - as you refine your preferences, the decision tree takes over to narrow down the set of tickets that match your preferences.
Random Forest: The Random Forest is one of the leading classification algorithms in machine learning. The Random Forest gets its name from the fact it takes a random sampling of training data set when building trees and random subsets of features are considered when splitting nodes. Random Forest's are really intuitive: it consists of a large number of individual decision trees that operate as an ensemble. Each individual tree in the random forest generates a class prediction. The model's prediction is simply the class with the most votes.
The theory behind Random Forests are especially applicable to the stock market: wisdom of crowd's. So, they key is to utilize individual forest's that are uncorrelated.
Retailers can utilize these models by feeding various product characteristics or variables into the model and use a random forest to indicate potential customer interest. This allows the company to narrow down the importance of each product variable to a customer's decision to buy the product.
Support Vector Machines ("SVM"): Support-Vector Machines are supervised learning models which use associated learning algorithms to analyze data for classification and regression analysis. SVMs are used for pattern recognition by finding the optimal hyperplane (a line in 2-D space separator) for patterns that can be sorted in a linear manner. It uses the "kernel trick" to transform data. Then based on these transformations, it finds an optimal boundary between the possible outputs by maximizing the distance between the hyperplane and data points.
SVMs are currently being used for tasks like credit risk modeling, face detection, image classification, bioinformatics, and text categorization.
Bayesian Networks: Also known as decision networks, take an event that occurred and predict the likelihood that any one of several possible known causes was the contributing factor. Each node in the network is associated with a probability function that takes a set of values as inputs for the node's parent variables. The outputs are the probability (or probability distribution) of the variable represented by the node. The ideal Bayesian Network can perform both inference and learning.
An example in medical diagnoses is representing the probabilistic relationships between diseases and symptoms. Meaning that given symptoms, the network can be used to compute the probabilities of the presence of various diseases.
Genetic Algorithms: These are stochastic search algorithms which act on a set of possible solutions. Genetic algorithms are rooted in the mechanics of population genetics and selection. Potential solutions can be thought of as "genes" and new solutions can be created from "mutations" within the existing population (set) or by two existing solutions coming together to form a new solution. It can be thought of as a random probabilistic search function.
As an example, complies like Aria Networks use genetic algorithm-based technology for problems such as optimizing business networks and identifying genetic patterns that are associated with specific diseases.
A Framework for Determining AI/ML Value
The Harsh Reality
BAI is table stakes and aside from streamlining certain operations, it does not provide anywhere near a sustainable competitive advantage. Yes, streamlining operations yields cost savings and can increase productivity. But if (almost) every company is doing it, by definition it is not a sustainable competitive advantage. Once certain processes have been put in place, there is no further incremental value add. Is the company you're analyzing using BAI? Don't count on it being the reason why it can outperform its competition over a long period of time.
Even if what the company is describing is truly ML, it may be table stakes depending on a variety of factors. Once again, there are no shortcuts to determining if a company's usage of AI is valuable or not. Since we have already ruled out BAI as a source of a sustainable competitive advantage ("moat"), we will focus on how to determine how much of an advantage a company's ML usage is.
In most cases, a company with a data advantage will be better off than a company with an algorithm advantage. To be clear, better algorithms can process data more efficiently and potentially reach solutions sooner than an otherwise inferior algorithm. However, without unique or superior data, a great algorithm isn't necessarily a game changer.
The Variables that Matter
When analyzing the potential value added by companies claiming to use AI (as a blanket statement), there are certain critical components that help build a mosaic. These components, the importance of which will change as the technology evolves, are: 1) Data quantity, 2) Data velocity, 3) Data quality/richness, 4) Algorithm novelty, and most importantly 5) The type of problem being solved. I cannot stress the importance of number five enough. A company that develops data and algorithms that can solve a previously "impossible" problem generates significantly more value from ML than a company that
Speaking of variables, a quick heuristic for understanding how powerful ML can be is by identifying the number of variables driving the model. For example, Tesla's automated driving algorithm is a lot more powerful than an OTAs sorting model. Tesla is processing countless random variables at all times, while the OTA sorting model is based on a relatively small amount of discrete variables.
There is no shortcut for understanding exactly what these companies are doing. Are they using existing / open-source algorithms? Are they buying their data? How easy is it for them to replicate this data? Or are they creating everything in-house?
The Framework and Process

This graphic that Tyler put together says more than I could in this section. Going left to right, from low to high value, you can think of as low being table stakes and high being true value add for the company which creates a sustainable competitive advantage. There is a rough correlation between data velocity and quantity , but I recommend thinking about the two separately to start. A company can backfill a large pool of data. However, if the company's business yields a low data velocity the value of ML will be diminished. To reiterate, there is no other way to complete this analysis without doing real field work. You need to talk to experts and people familiar with the company's tech to develop a thorough understanding of how the company utilizes ML.
The analytical sequence I recommend is as follows:
What problem is the company trying to solve?
Low: Solely improving an existing solution to a problem.
Medium: Creating a solution to a previously unsolved problem.
High: Solving a problem that was previously thought to be impossible.
Has the company created a new algorithm to solve the problem?
Low: Utilizes an open-source, widely available API / off-the-shelf algorithm.
Medium: Customizes an open-source algorithm.
High: Creates a novel and unique algorithm from scratch.
Where does the company obtain and collect the data?
Low: Buys third-party data from a provider.
Medium: Buys third-party data to supplement proprietary data.
High: Only proprietary data is used.
How dense or rich is the data being collected by the company?
Low: Obtains plain text from files or other sources.
Medium: Audio files are obtained instead of or in addition to plain text.
High: Video files are the predominant data source.
How quickly is the company providing the algorithm with new data (turnover)?
Low: Infrequent data sources such as regulatory filings
Medium: Intermittent interactions with customers like chatbots.
High: Continuous data feedback like social media websites or posts.
How much data does the company currently have and is it proprietary?
Low: Startup company with no existing data set
Medium: Growth company that is accumulating data at an increasing rate
High: Company has a vast data repository built over many years of operations
We can apply this framework to any company claiming to use ML. I get a basic understanding of where the company may rank simply by adding up the scores (1-3) of each segment. But this is not a quantitative process. Similar to how you build a mosaic for analyzing a company by collating many data points, we are doing the same thing here. The analysis of the potential for a sustainable competitive advantage from utilizing ML is a mosaic resulting from the above questions. The Venn diagram below illustrates the importance of each component.

Levels of Value
The following levels of value in order from least valuable to most valuable are below. Notice how proprietary data is at a higher level for a given algorithm novelty.
Company uses off-the-shelf algorithms (such as Azure, OpenAI APIs)
Company uses data to train off-the-shelf algorithms
(2.5) Proprietary data makes up >50% of full training dataset (scalability)
Company hosts and runs slightly modified algorithms (fine-tuning)
Company hosts and runs slightly modified algorithms using proprietary data
Company develops a completely novel algorithm
Company develops a completely novel algorithm with proprietary data
Commercial Machine Learning
To conclude this primer on AI, we will look at some commercial use cases and quickly try to understand the value of ML used by some companies. I am not providing any sort of company analysis or recommendation, that requires a full scale newsletter itself. I am simply trying to provide some brief examples.
Google Search Algorithm: Solved a problem that was previously unsolved (website indexing), created a novel algorithm (PageRank), the data collected is plain text (I understand this is not literally correct), all of the data is obtained through its website, the velocity of data is staggering (~3.8 million searches per MINUTE or 2 trillion searches per year), vast data repository is an understatement.
While a 15/18 score is excellent - the sustainable competitive advantage is evident since many search engines have tried to compete with Google and failed (i.e. Yahoo, Bing, etc.)

Natural Language Processing - NLP may be the second most commonly used application of ML. NLP is of huge value to companies that rely on predicting what your next desire will be. It is of way less value to companies like Lemonade that use it to be more personable and lifelike in a chat.
GPT-3: Remember this from Part III? Well, GPT-3 is the the most advanced NLP program out there with 175B parameters and the ability to create text documents based on a few inputs. While it still has a long way to go, the results are remarkable and very exciting for those in the field.
Virtual Assistants: Siri, Amazon Alexa, Google Assist Each of these companies are improving on an existing solution, created a novel NLP algorithm, both proprietary and third-party data is used, the data collected is audio, the velocity of data is once again staggering, and each company continues to collect a vast repository of data.
Once again, the ML quality is scoring a 14/18. But taking a qualitative view, I don't need to tell you how much these "virtual assistants" still struggle with some basic tasks (try to tell Siri a "knock knock" joke. Is the virtual assistant of Google, Apple, or Amazon the differentiating factor in someone's purchase decision? Probably not. But if a company perfects the virtual assistant then that may be a game changer.
Chatbots: More chats simply improve the quality of the interactions between bot and customer, but provides no further benefit aside from customer satisfaction and some labor savings.
Lemonade: As an example, LMND is simply optimizing something that already existed, using off-the-shelf algorithms, through both obtained and proprietary data, with plan text data, medium frequency given the chatbot nature, and a moderate amount of data given how it's a young company. Understanding chatbots are table stakes in customer service departments, this does not provide any sort of advantage to LMND.
Image Classifiers / Image Recognition
Generative Adversarial Network ("GAN"): Developed in 2014, GANs consist of two neural networks essentially competing with each other in a zero-sum game in which the generative network tries to fool the discriminative network. This is done after each network learns from a training data set. GANs can be used to generate new images that look superficially authentic to humans.
Common applications are image creation in gaming (characters, settings, etc.), anonymity protection, medical studies, and increasing in popularity is virtual hosts for YouTube videos.

DeepFace - Facebook’s DL Facial Recognition: DeepFace utilizes Deep Learning models to 1) Detect, 2) Align, 3) Represent, and 4) Classify the face. All users of Facebook trained the model by tagging themselves in photos. While the actual underlying technology is a bit unclear to me, my take is that it solved a problem that was previously unsolved, uses a novel algorithm, with photographs uploaded to its website, photographic data, high frequency or data velocity as social media, and with 2.7B monthly active users - A LOT of data.
This has certainly given Facebook a product edge and may have solidified itself as a permanent social media company, which was previously a transient part of society (MySpace!).
Pinterest Visual Search: Pinterest uses computer vision models to "see" the content of everything posted to the site and filter out inappropriate content. They even have a dedicated page to explain their ML / DL projects.
Solved a problem that was previously unsolved, using TensorFlow (open-source), through third-party and proprietary images, visual data (between audio and video), social media is a high velocity data platform, and given its userbase the data quantity is massive. This seems to provide a healthy advantage for PINS.
Other Common Examples
These are just some examples of how Machine Learning pervades our every day lives, even if we don't realize it. Apple or Google article recommendations based on your prior reading history is the result of a ML algorithm. Video or movie recommendations from YouTube or Netflix, price recommendations on the sell and buy-side on Airbnb or Amazon, ad infinitum - the result of ML.
There are so many more examples and broader use cases like speeding up software, financial trading algorithms, machine / transportation design models - find some more examples through research in your down time... it's fascinating!
It's important to reiterate why data is currently more important than the algorithm. Algorithms change, but the training data likely doesn't. So for a company like Spotify, where listening data is unique, valuable, and critical; the algorithms could be easily interchanged but the data would stay the same. And that is what makes the ML used by some of these companies so valuable.
Conclusion
The intention of this article was to provide insight into the current commercial use cases of AI and how to determine if and how much ML can add value to a company. I provided a high level framework to help you differentiate between companies developing a sustainable competitive advantage through ML and those that are simply improving operations just like its competitors.
So what is the takeaway? If there is one thing I want you to take away from this write up is that assuming a durable, lasting competitive advantage from ML is almost always a bad idea. As an example, GANs just came out about six years ago! Any previous "best" got blown out of the water. These technologies are transient and the industry is improving at a faster rate than even the computer processing industry can keep up with. Even CrowdStrike, a company that I have long favored, is not immune to this technological innovation (although I think CRWD's downfall won't be related to AI, but rather quantum encryption).
I am not an AI expert, far from it. I developed this Primer in order to learn in public and you all could follow along. This is my current best shot at trying to apply my learnings to the investment process. I would love to hear from you all as to what I may have missed / should add, how I may be wrong, or even if you agree. With that, I hope you enjoyed the first Primer from Seifel Capital.
Great read, Christopher! Will revisit this frequently.